Brief Review — A Real-Time Snore Detector Using Neural Networks and Selected Sound Features
Real-Time Snore Detector (RTSD)
A Real-Time Snore Detector Using Neural Networks and Selected Sound Features
RTSD, by University of West Attica
2021 MDPI J. EngProc (Sik-Ho Tsang @ Medium)Snore Sound Classification
2017 … 2020 [Snore-GAN] 2021 [ZCR + MFCC + PCA + SVM] [DWT + LDOP + RFINCA + kNN]
==== My Healthcare and Medical Related Paper Readings ====
==== My Other Paper Readings Are Also Over Here ====
- A Real-Time Snore Detector (RTSD) is developed for screening OSAHS at home, which discriminates snoring vs. environmental sounds using sound features and ANN.
Outline
- Scalar Features + Normalized MSC + ANN
- Real-Time Snore Detector (RTSD)
1. Scalar Features + Normalized MSC + ANN

1.1. Preprocessing
- Sound excerpts are used as input to the classification tool.
- The input sound recording is parsed with a sliding window of duration 6 s and a sliding step of 2 as a typical breathe-in-breathe-out cycle is about 4 s.
- Each sound excerpt is de-noised using wavelet filtering and then normalized with respect to its average energy.
1.2. Feature Extraction
- Selected features are calculated for each sound excerpt (sampled at 48 kHz, 24-bit), including temporal (time-domain), spectral (frequency-domain) and time-frequency features (GMM).
- The first features subset that we opted to compare consists of scalar features, including (i) the ZCR, pitch, bandwidth, volume, and intensity of the signal, (ii) a set of entropy metrics, specifically the Shannon, Tsallis, wavelet, and permutation entropy, and (iii) a few statistical metrics, namely the median, average, variance, skewness, and kurtosis of the signal amplitude.
- The second features’ subset includes the MFCCs of the sound signal; more specifically, 13 MFCCs are calculated over the frequency range between 20 Hz and 6 kHz of the recorded signal.
- A modified spectrogram is also developed. Each sound excerpt is down-sampled to 12 kHz. Hence the resulting spectrogram ranges from 0 up to 6 kHz. Then, the average spectral coefficients in adjacent are calculated, non-overlapping windows of length 100 Hz each, resulting to the so-called modified spectral coefficients (MSC).

MSC shows higher test set accuracy.

Given that scalar features are computationally less intensive than MFCC to calculate, normallized MSC plus scaler features are used.
1.3. ANN
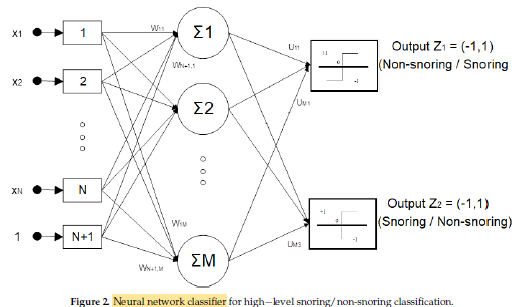
- RTSD will ultimately run in smartphones at home, a shallow neural network classifier with one hidden layer is used.
- The number of nodes of the network hidden layer was selected to be equal to (rounded) 2.5 times the number of nodes of the network input layer.
2. Real-Time Snore Detector (RTSD)

A set of twenty-five whole-night sound recordings is used, other than those used for the training and testing of the classification tool, in order to test the proposed RTSD.
- The total duration of the whole-night recordings that were tested is equal to 51 h, 45 min and 13 s. A total of 12,090 different sound excerpts of duration 6 s each are classified as snoring by the RTSD, corresponding to a total duration of 20 h and 9 min. (These snoring sound excerpts are freely available to the interested reader upon request)
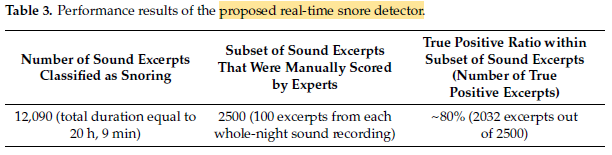
Out of 2500 tested excerpts, a total of 2032 (or about 80%) were scored as snoring.
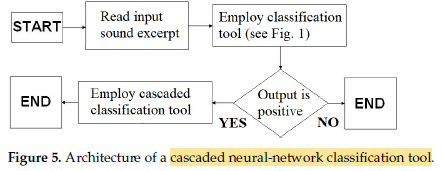
The above cascaded classification is to be done in the future.
