Brief Review — GAN-CLS-INT: Generative Adversarial Text to Image Synthesis
Proposes Matching-Aware Discriminator (GAN-CLS), Learning with Manifold Interpolation (GAN-INT), & Combined One (GAN-CLS-INT)

Generative Adversarial Text to Image Synthesis
GAN-CLS, GAN-INT, GAN-CLS-INT, by University of Michigan, and Max Planck Institute for Informatics,
2016 ICML, Over 3200 Citations (Sik-Ho Tsang @ Medium)Generative Adversarial Network (GAN)
Image Synthesis: 2014 … 2019 [SAGAN]
==== My Other Paper Readings Are Also Over Here ====
- A novel deep architecture and GAN formulation are proposed to effectively bridge these advances in text and image modeling, translating visual concepts from characters to pixels.
Outline
- Proposed GAN for Text to Image Synthesis
- Results
1. Proposed GAN for Text to Image Synthesis

- In the generator G, the noise prior z is first sampled. The text query t using text encoder φ, then concatenated to the noise vector z. A synthetic image ^x is generated.
- In the discriminator D, at the near end, the description embedding is replicated spatially and a depth concatenation is performed.
1.1. Matching-Aware Discriminator (GAN-CLS)

- In naive GAN, the discriminator observes two kinds of inputs: real images with matching text, and synthetic images with arbitrary text. Therefore, it must implicitly separate two sources of error: unrealistic images (for any text), and realistic images of the wrong class that mismatch the conditioning information.
- Based on the intuition that this may complicate learning dynamics, the GAN training algorithm is modified to separate these error sources.
A third type of input is added, which consists of real images with mismatched text, which the discriminator must learn to score as fake, i.e. code line 8 as shown in the Algorithm 1 above.
1.2. Learning With Manifold Interpolation (GAN-INT)
A large amount of additional text embeddings can be generated by simply interpolating between embeddings of training set captions.
- Critically, these interpolated text embeddings need not correspond to any actual human-written text, so there is no additional labeling cost.
- This can be viewed as adding an additional term to the generator objective to minimize:

- β=0.5 works well.
And GAN-INT can be combined with GAN-CLS as GAN-CLS-INT.
1.3. Inverting the Generator for Style Transfer
If the text encoding φ(t) captures the image content (e.g. flower shape and colors), then in order to generate a realistic image the noise sample z should capture style factors such as background color and pose. With a trained GAN, one may wish to transfer the style of a query image onto the content of a particular text description.
- To achieve this, one can train a convolutional network to invert G to regress from samples ^x ← G(z, φ(t)) back onto z. A simple squared loss is used to train the style encoder:
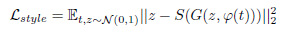
- where S is the style encoder network.
- With a trained generator and style encoder, style transfer from a query image x onto text t proceeds as follows:
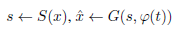
- where ^x is the result image and s is the predicted style.
2. Results
2.1. Bird Images

GAN and GAN-CLS get some color information right, but the images do not look real. However, GAN-INT and GAN-INT-CLS show plausible images that usually match all or at least part of the caption.
2.2. Flower Images

- All four methods can generate plausible flower images that match the description. Maybe this dataset is easier.
2.3. Interpolating Two Sentences

Interpolations can accurately reflect color information, such as a bird changing from blue to red while the pose and background are invariant.
2.4. Style Transfer

Style transfer preserves detailed background information such as a tree branch upon which the bird is perched.
