Brief Review — GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium
Proposes Two Time-scale Update Rule (TTUR) and Fréchet Inception Distance (FID)
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium
TTUR, Fréchet Inception Distance (FID), by Johannes Kepler University Linz
2017 NIPS, Over 8500 Citations (Sik-Ho Tsang @ Medium)Generative Adversarial Network (GAN)
Image Synthesis: 2014 … 2019 [SAGAN]
==== My Other Paper Readings Are Also Over Here ====
- Two Time-scale Update Rule (TTUR) is proposed for GAN training.
- Fréchet Inception Distance (FID) is also proposed as a metric to measure the generated quality, which is better than Inception Score (IS).
Outline
- Two Time-scale Update Rule (TTUR)
- Fréchet Inception Distance (FID)
- Results
1. Two Time-scale Update Rule (TTUR)

TTUR has an individual learning rate for both the discriminator and the generator, which is better than using same learning rate situations as above.
- And GANs can converge to a local Nash equilibrium when trained by a TTUR, i.e., when discriminator and generator have separate learning rates.
- For a two time-scale update rule (TTUR), the learning rates b(n) and a(n) are used for the discriminator and the generator update, respectively:

2. Fréchet Inception Distance (FID)
“Fréchet Inception Distance” (FID) is the Fréchet distance d(., .) between the Gaussian with mean (m, C) obtained from p(.) and the Gaussian with mean (mw, Cw) obtained from pw(.) the , which is given by:

- For computing the FID, all images are propagated from the training dataset through the pretrained Inception-v3 model following the computation of the Inception Score. However, the last pooling layer is used as coding layer. For this coding layer, the mean mw and the covariance matrix Cw are calculated.
- To approximate the moments for the model distribution, 50,000 images are generated, propagated through the Inception-v3 model, and then the mean m and the covariance matrix C are computed.

- Noises with different noise levels and different types are added to CelebA images as above.
Fréchet Inception Distance (FID) captures the disturbance level very well. FID is more consistent with the noise level than the Inception Score.
3. Results
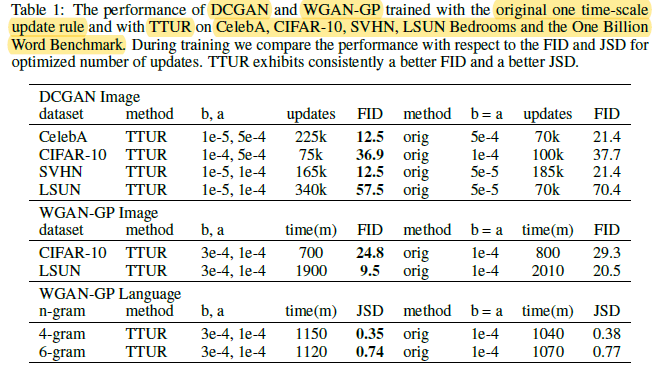
- FID is used for image evaluation.
- Jensen-Shannon-divergence (JSD) is used for language benchmark.
Using TTUR obtains better performance than the original training strategy.
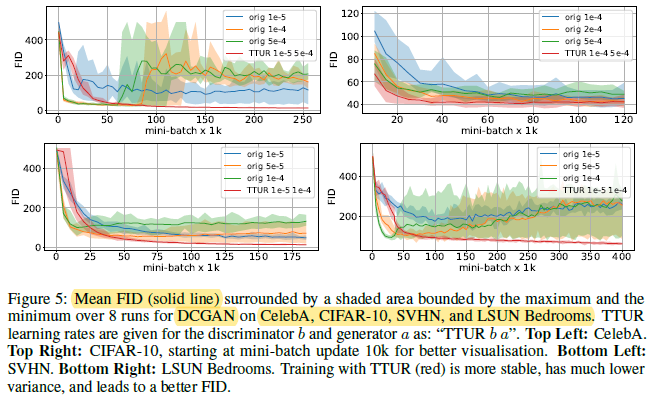
The best FID is obtained with TTUR. TTUR constantly outperforms standard training and is more stable.
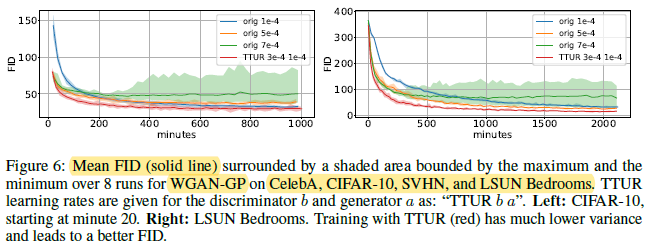
Again TTUR reaches lower FIDs than one time-scale training.

The improvement of TTUR on the 6-gram statistics over original training shows that TTUR enables to learn to generate more subtle pseudo-words which better resembles real words.
