Brief Review — Medical Image Segmentation Based on Self-Supervised Hybrid Fusion Network

Medical Image Segmentation Based on Self-Supervised Hybrid Fusion Network,
Multi-Modal ResUNet+ASPP+HAFB, by 1Dalian University of Technology, 2The First Affiliated Hospital of Dalian Medical University, and 3The Affiliated Central Hospital, Dalian University of Technology
2023 Frontiers in Oncology (Sik-Ho Tsang @ Medium)Biomedical Image Self-Supervised Learning
2018 … 2022 [BT-Unet] [Taleb JDiagnostics’22] [Self-Supervised Swin UNETR] [Self-Supervised Multi-Modal]
==== My Other Paper Readings Are Also Over Here ====
Outline
1. Brief Review of Multi-Modal ResUNet+ASPP+HAFB
- Indeed, the model architecture and loss function is almost the same as the one in Self-Supervised Multi-Modal (2022 JHBI). (So, I don’t repeat here too much. Please feel free to read the story directly.)
A self-supervised multi-modal encoder-decoder network is proposed based on ResNet as shown at the top where HAFB enables the feature learning using images from multi-modalities.

The network introduces a multi-modal Hybrid Attentional Fusion Block (HAFB) to fully extract the unique features of each modality and reduce the complexity of the whole framework.
- One input is features from other modalities. Another input is features from the same modality but at the higher level.

In addition, to better learn multi-modal complementary features and improve the robustness of the model, a pretext task is designed based on image masking.
- By masking, inputs become not the same from x to x’, similarity loss is added to enforce them to be the same at feature level even one of them is masked.
2. Results
- Besides BraTS 2019 dataset which is evaluated in 2022 JBHI (with different result values), BraTS 2020 is also evaluated.
2.1. BraTS 2020

The proposed model obtains the best results on ET and WT.
2.2. Ablation Study
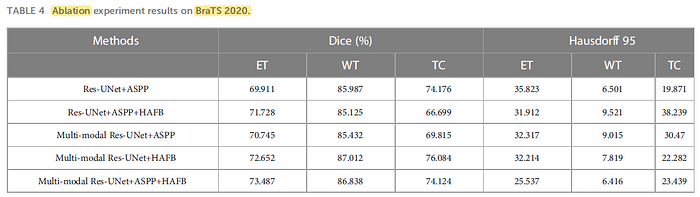
With the ASPP module (last row), although there is no significant improvement in the dice coefficient, ASPP module performs feature extraction from multiple scales on the feature map at the end of the encoder, which makes it more accurate for edge information extraction.
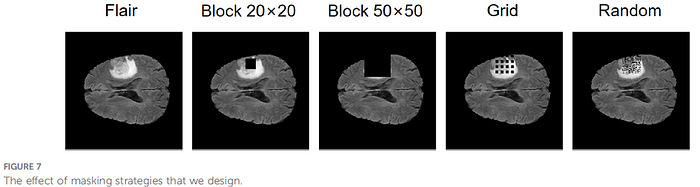
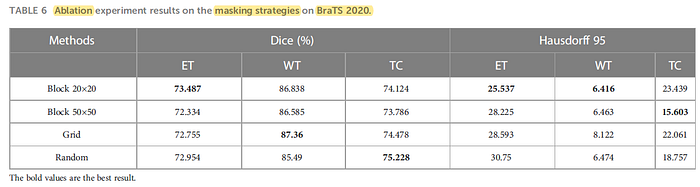
All these masking strategies are able to make the self-supervised strategy effective and make the model accuracy improve. Overall, the best performer is the 20×20 square mask.
