Brief Review — Snore Sound Classification Using Image-based Deep Spectrum Features

Snore Sound Classification Using Image-based Deep Spectrum Features
AlexNet & VGG-19 for Snore Sound Classification, by Universität Passau, Technische Universität München, and Imperial College London
2017 InterSpeech, Over 310 Citations (Sik-Ho Tsang @ Medium)Snore Sound Classification
2017 [InterSpeech 2017 Challenges: Addressee, Cold & Snoring] 2018 [MPSSC]
==== My Healthcare and Medical Related Paper Readings ====
==== My Other Paper Readings Are Also Over Here ====
1. AlexNet & VGG-19 for Snore Sound Classification
1.1. Background
- Snoring can also be a marker of Obstructive Sleep Apnea (OSA) [3] which, after insomnia, has the highest prevalence of all sleep disorders, affecting approximately 3–7% of the middle-aged men and 2–5% of middle-aged women [4–6] in the general population.
- OSA is characterised by repetitive episodes of partial or complete collapses of the upper airway during sleep, causing impaired gaseous exchanges and sleep disturbance [7].
- As a chronic condition that is caused by an obstruction of the upper airways during sleep, OSA can lead to an increased risk of cardiovascular and cerebrovascular diseases [8, 9].
1.2. Spectrogram

The snore samples are transformed into a format that can be processed by the pre-trained CNNs by creating spectrograms of the audio files.
Hanning windows of width 16 ms, and overlap 8 ms, are used and the power spectral density is estimated on the dB power scale.
- 3 color mappings are used:
- jet which is the default colour map of matplotlib and varies from blue (low range) to green (mid range) to red (upper range);
- gray which is a sequential grey-scale mapping which varies from black (low range) to grey (mid range) to white (upper range); and finally,
- viridis which is a perceptually uniform sequential colour map varying from blue (low range) to green (mid range) to yellow (upper range).
- The spectrograms have an intermediate size of 387×387 pixels, and are then further scaled down to 224×224 (for VGG-19) and 227×227 pixels (for AlexNet).
Even with the human eye, some clear distinctions between the spectrograms of different classes can be made, as shown above.
1.3. AlexNet & VGG-19

- The models and weights for AlexNet and VGG-19 are obtained via the publicly available CAFFE toolkit.
1.4. SVM
- Four classes are to be classified, which reflect the place of obstruction causing the snore: Velum (V), Oropharyngeal (O), Tongue (T), and Epiglottis (E).
- This is achieved by training linear SVM on the extracted feature sets.
- The INTERSPEECH 2017 ComParE Snoring sub-challenge is based on the Munich-Passau Snore Sound Corpus, which contains 828 snore samples from four classes.
- The classes have uneven distribution, with substantially more V samples [11]. Therefore upsampling is performed by replicating samples from the O, T, and E classes.
2. Results

The best results are achieved with features extracted from AlexNet’s fc7 layer and the spectrogram colour map viridis.
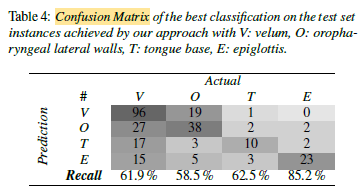
The confusion matrix of classification labels on the test set for this best performing system is displayed in Table 4.
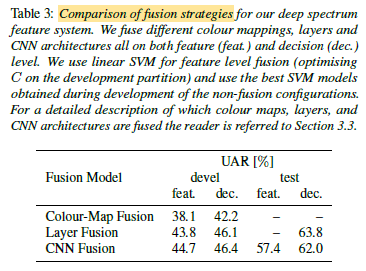
Fusing features extracted from spectrograms of different colour maps decreases performance for both feature and decision level fusion compared to only using the best colour map. The performance decrease might be caused by the increased feature size.
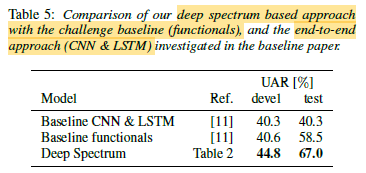
An UAR of 44.8% on the development, and 67.0% on the test partition, are achieved, outperforming the challenge baseline system, as in Table 5.
