Brief Review — Snoring classified: The Munich-Passau Snore Sound Corpus
MPSSC Dataset is Proposed

Snoring classified: The Munich-Passau Snore Sound Corpus
MPSSC, by Technische Universität München, Universität Passau, University of Augsburg, Imperial College London, Alfried Krupp Krankenhaus, and Carl-Thiem-Klinikum
2018, J. Comp Bio Med, Over 50 Citations (Sik-Ho Tsang @ Medium)Snore Sound Classification
2017 [InterSpeech 2017 Challenges: Addressee, Cold & Snoring]
==== My Healthcare and Medical Related Paper Readings ====
==== My Other Paper Readings Are Also Over Here ====
- In this paper, a database of snore sounds is introduced. Video and audio recordings taken during drug induced sleep endoscopy (DISE) examinations from three medical centres have been semi-automatically screened for snore events, which subsequently have been classified by ENT experts into four classes based on the VOTE classification.
- The resulting dataset containing 828 snore events from 219 subjects.
- A SVM classifier is trained on different feature sets.
- The data of the MPSSC was introduced as the Snore Sub-Challenge in the INTERSPEECH 2017 Computational Paralinguistics ChallengE (COMPARE).
Outline
- Munich-Passau Snore Sound Corpus (MPSSC) Dataset
- Benchmarking Results
1. Munich-Passau Snore Sound Corpus (MPSSC) Dataset
1.1. Data Collection
- The material is available in mp4 format and contains simultaneous video and audio recordings.
- The recordings were made during DISE examinations of patients who had undergone previous polysomnography (PSG) and were diagnosed with OSA.
- The material was obtained from three clinical centres.

- The VOTE classification distinguishes four structures that can be involved in airway narrowing and obstruction.
- V, Velum (palate), including the soft palate, uvula, and lateral pharyngeal wall tissue at the level of the velopharynx.
- O, Oropharyngeal lateral walls, including the palatine tonsils and the lateral pharyngeal wall tissues that include muscles and the adjacent parapharyngeal fat pads.
- T, Tongue, including the tongue base and the airway posterior to the tongue base.
- E, Epiglottis, describing folding of the epiglottis due to decreased structural rigidity or due to posterior displacement against the posterior pharyngeal wall.
- To record the sound, different centres use different equipment, such as headset microphone, stand-mounted microphone, handheld microphone, etc.

All segments exceeding a level of two times the determined background noise level for a minimum duration of 300 ms were annotated. Adding 100 ms of signal before and after the actual onset and end of the event, the events were extracted from the original audio file, normalised, and saved as separate wav files.

There are data selection steps as above to further select qualified snore sound.
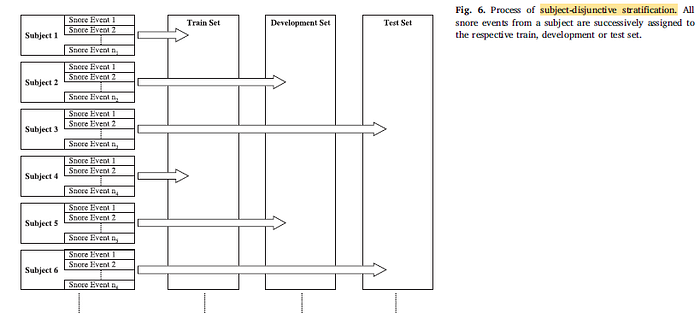
- Each subject only belongs to train, val, or test set only.
- In particular, an even distribution of the data by centre is also used to reduce the risk of learning ambient acoustic characteristics instead of snore sound properties.
1.2. Dataset Properties

The resulting database contains audio samples of 828 snore events from 219 subjects.
- Average sample duration is 1.46 s (range 0.73 … 2.75 s). Average age of the subjects is 49.8 (range 24 … 78) years.
- Further, notably, 93.6% of all subjects are male.
The number of events and subjects per class in the database is strongly unbalanced, with the majority of samples belonging to the V and O class (total 84.5%), whereas T and E type snoring samples only account for 4.7%, and 10.8%, respectively.
2. Benchmarking Results
2.1. Features

- A set of features is collected as above to train SVM classifier.
2.2. Results
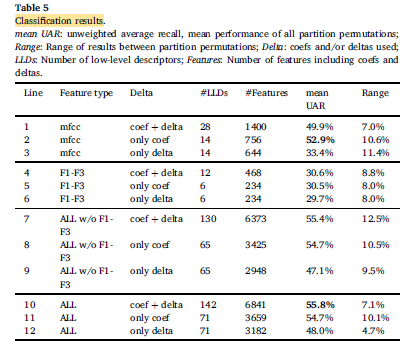
- The classification results for the best-performing feature sets together with the corresponding number of LLDs and the final number of features after computing the functionals, are shown above.
The best classification performance could be achieved with the full feature set consisting of the COMPARE features plus the formant set F1-F3 including functionals and deltas.
Best performing single subset is mfcc only coef, consisting of MFCC-related LLDs, using functionals, but not deltas.
- Using only formant-related features (F1-F3) yielded inferior classification results.
- Removing the formants subset from the full feature set results in only a minor deterioration of 0.4% UAR.
- (There are also confusion matrices, recalls in the paper, please feel free to read the paper directly.)
