Brief Review — WGAN: Wasserstein Generative Adversarial Networks
WGAN, Improve GAN Stability

Wasserstein Generative Adversarial Networks
WGAN, by Courant Institute of Mathematical Sciences, and Facebook AI Research (FAIR)
2017 ICML, Over 13000 Citations (Sik-Ho Tsang @ Medium)Generative Adversarial Network (GAN)
Image Synthesis: 2014 … 2019 [SAGAN]
==== My Other Paper Readings Are Also Over Here ====
- GAN training is unstable and may have mode collapse. With WGAN, training becomes stable.
Outline
- WGAN
- Results
1. WGAN
- (Since there is a lot of blogs explaining WGAN in very details. Here, I would rather provide a very short article.)
1.1. Problem of Standard GAN
- In standard GAN, two-player min max game is used to train the discriminator and generator. Log function is used.

- The training is not stable, and also may cause mode collapse.
1.2. WGAN

- Sigmoid is removed, The discriminator becomes critic.
- The critic and generator do not use log function any more and the loss is formulate as below:

The original discriminator learns very quickly to distinguish between fake and real, and as expected provides no reliable gradient information.
The critic, however, can’t saturate, and converges to a linear function that gives remarkably clean gradients everywhere.
- After that, weight clipping clip(.) is used.
- When using RMSProp is fine for gradient descent, yet it is found that using Adam causes the loss blew up and samples got worse.
WGAN is summarized as below:
- (Lines 3–4): Each time, sample a batch of real samples, as well as a batch of fake samples from distribution z.
- (Lines 5): f is the critic model and g is the generator. The output layer of the critic model f is the linear activation function instead of sigmoid.
- Take the average prediction for real samples x from the critic model f, minus the average prediction for fake samples g(z) from the critic model f.
- (Lines 6–7): RMSProp, one of the standard weight update algorithms, is used to updated w. This w is clipped in range of [-c, c].
- (Lines 9–11): A batch of fake samples from distribution z is sampled. This time, the average prediction for fake samples g(z) from the critic model f to update the generator through RMSProp.
2. Results

- This is the first time in GAN literature that such a property is shown, where the loss of the GAN shows properties of convergence.
The lower the loss, the better sample quality.
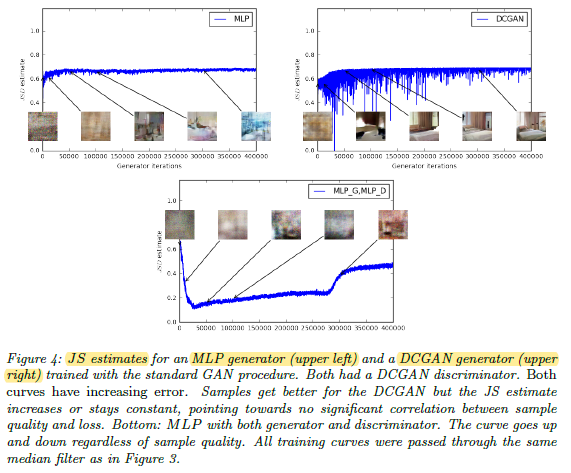
However, if using JS, the loss cannot reflect the quality proportionally.

- The above figures show the samples generated for these three architectures using both the WGAN and GAN algorithms.
- Particularly in Figure 6, Standard GAN fails when the model does not use batch norm and constant number of filters at every layers while WGAN still can work well.
Authors also mentioned that they cannot see evidence of mode collapse for the WGAN algorithm during all experiments.
