Reading: UNet 3+ — A Full-Scale Connected UNet (Medical Image Segmentation)
Outperforms UNet++, Attention UNet, UNet, PSPNet, DeepLabV2, DeepLabV3 and DeepLabV3+

In this story, UNet 3+, by Zhejiang University, Sir Run Run Shaw Hospital, Ritsumeikan University, and Zhejiang Lab, is briefly presented. UNet++ uses nested and dense skip connections, but it does not explore sufficient information from full scales. In UNet 3+, full-scale skip connections and deep supervisions are used:
- Full-scale skip connections: incorporate low-level details with high-level semantics from feature maps in different scales.
- Full-scale deep supervision: learns hierarchical representations from the full-scale aggregated feature maps.
- A hybrid loss function and a classification-guided module (CGM) are further proposed.
This is a paper in 2020 ICASSP. (Sik-Ho Tsang @ Medium)
Outline
- Full-Scale Skip Connection
- Full-scale Deep Supervision
- Experimental Results
1. Full-Scale Skip Connection

- Both UNet with plain connections and UNet++ with nested and dense connections are short of exploring sufficient information from full scales, failing to explicitly learn position and boundary of an organ.
- Each decoder layer in UNet 3+ incorporates both smaller- and same-scale feature maps from encoder and larger-scale feature maps from decoder, which capturing fine-grained details and coarse-grained semantics in full scales.

- To construct the feature map of 𝑋3De, similar to the UNet, the feature map from the same-scale encoder layer 𝑋3En.
- In contrast to the UNet, a set of inter encoder-decode skip connections delivers the low-level detailed information from the smaller-scale encoder layer 𝑋1En and 𝑋2En , by applying non-overlapping max pooling operation.
- A chain of intra decoder skip connections transmits the high-level semantic information from larger-scale decoder layer 𝑋4De and 𝑋5De, by utilizing bilinear interpolation.
- For the sake of the channel reduction, the parameters in UNet 3+ is fewer than those in UNet and UNet++. (There are mathematical proofs here, if interested, please feel free to read the paper.)
2. Full-scale Deep Supervision

2.1. Deep Supervision
- UNet 3+ yields a side output from each decoder stage (Sup1 to Sup5), which is supervised by the ground truth.
- To realize deep supervision, the last layer of each decoder stage is fed into a plain 3 × 3 convolution layer followed by a bilinear up-sampling and a sigmoid function.
2.2. Loss Function
- Multi-Scale Structural SIMilarity index (MM-SSIM) loss is used to assign higher weights to the fuzzy boundary.
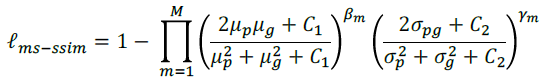
- Focal loss, originated in RetinaNet, is used, to deal with the class imbalance problem.
- Standard IoU loss is used.
- Thus, a hybrid loss is developed for segmentation in three-level hierarchy — pixel-, patch- and map-level, which is able to capture both large-scale and fine structures with clear boundaries:
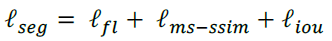
2.3. Classification-Guided Module (CGM)
- There are false-positives in a non-organ image.
- This may be caused by noisy information from background remaining in shallower layer, leading to the phenomenon of over-segmentation.
- To solve this problem, an extra classification task is added, for predicting the input image whether has organ or not.
- As shown in the figure above, after passing a series of operations including dropout, convolution, maxpooling and sigmoid, a 2-dimensional tensor is produced from the deepest-level 𝑋5En, each of which represents the probability of with/without organs.
- With the help of the argmax function, 2-dimensional tensor is transferred into a single output of {0,1}, which denotes with/without organs.
- Subsequently, the single classification output is multiplied with the side segmentation output.
- Binary cross entropy loss function is used to train the CGM.
3. Experimental Results
3.1. Datasets
- The dataset for liver segmentation is obtained from the ISBI LiTS 2017 Challenge. It contains 131 contrast-enhanced 3D abdominal CT scans, of which 103 and 28 volumes are used for training and testing, respectively.
- The spleen dataset from the hospital passed the ethic approvals, containing 40 and 9 CT volumes for training and testing.
- Images are cropped to 320×320.
3.2. Comparison with UNet and UNet++

- VGGNet and ResNet backbones are tested.
- UNet 3+ without deep supervision achieves a surpassing performance over UNet and UNet++, obtaining average improvement of 2.7 and 1.6 point between two backbones performed on two datasets.
- UNet 3+ combined with full-scale deep supervision further improved 0.4 point.

- UNet3+not only accurately localizes organs but also produces coherent boundaries, even in small object circumstances.
3.3. Comparison with the State of the Art
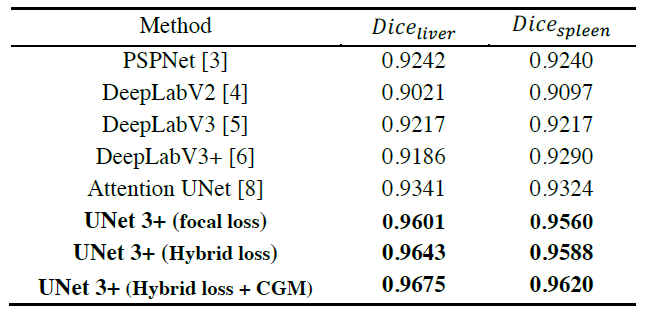
- All results are directly from single-model test without relying on any post-processing tools.
- The proposed hybrid loss function greatly improves the performance by taking pixel-, patch-, map-level optimization into consideration.
- Moreover, taking advantages of the classification-guidance module (CGM), UNet 3+ skillfully avoids the over-segmentation in complex background.
- Finally, UNet 3+ outperforms Attention UNet, PSPNet, DeepLabV2, DeepLabV3 and DeepLabv3+.
It has been a long time not reading paper about biomedical image segmentation.
This is the 1st story in this month !!!
Reference
[2020 ICASSP] [UNet 3+]
UNet 3+: A Full-Scale Connected UNet for Medical Image Segmentation
Biomedical Image Segmentation
[CUMedVision1] [CUMedVision2 / DCAN] [U-Net] [CFS-FCN] [U-Net+ResNet] [MultiChannel] [V-Net] [3D U-Net] [M²FCN] [SA] [QSA+QNT] [3D U-Net+ResNet] [Cascaded 3D U-Net] [Attention U-Net] [RU-Net & R2U-Net] [VoxResNet] [DenseVoxNet][UNet++] [H-DenseUNet] [DUNet] [MultiResUNet] [UNet 3+]
