Review: ResNet-38 — Wider or Deeper ResNet? (Image Classification & Semantic Segmentation)
A Good Compromise Between the Depth and Width, Outperforms DeepLabv2, FCN, CRF-RNN, DeconvNet, DilatedNet, Comparable with DeepLabv3, PSPNet.
In this story, ResNet-38, by University of Adelaide, is reviewed. By in-depth investigation of the width and depth of ResNet, a good trade-off between the depth and width of the ResNet model is found. It outperforms the original ResNet in image classification. Finally, it also has good performance in semantic segmentation. This is a 2019 JPR (Journal of Pattern Recognition) paper with over 200 citations. (Sik-Ho Tsang @ Medium)
Outline
- Unravelled View of ResNets
- Wider or Deeper?
- Image Classification Approach
- Semantic Segmentation Approach
- Image Classification Results
- Semantic Segmentation Results
1. Unravelled View of ResNets


- Above is the unravelled view of a simple ResNet with only two Residual Units.
- Some prior arts claimed that ResNet actually behaved as exponential ensembles of relatively shallow networks. However, the unravelled view cannot be treated as 4 shallow subnetworks: Ma, Mb, Mc, Md (Right of the figure).
- Instead, it can only be treated as Ma, Mb and Me1/Me2 only.
- Me cannot be further unravelled into Mc and Md.
- Therefore, it is hard to tell whether Me is well-trained, or “fully-trained”.
2. Wider or Deeper?
- In practice, algorithms are often limited by their spatial costs (GPU memory usages). One way is to use more devices, which will however increase communication costs among them.
- With similar memory costs, a shallower but wider network can have times more number of trainable parameters.
- And paths longer than the effective depth in ResNets are not “fully-trained”. That means, too deep ResNet cannot bring too obvious improvement or even worse.
3. Image Classification Approach

- Pre-Activation ResNet is used. That means for batch norm and ReLU are performed each convolution.
- Blue rectangle: Convolution step, Green triangle: Down-sampling,
- And there are B1-B7 residual units. For B1-B5, there are two 3×3 convolutions For B6-B7, bottleneck structure is used.
- When using input 224×224, B1 is removed due to limited GPU memory.
4. Semantic Segmentation Approach
- Resolution: To generate score maps at 1/8 resolution, down-sampling operations are removed and dilation rates are increased in some convolutions.
- Max pooling is harmful due to too strong spatial invariance.
- Classifier: One convolution is added to make the channel number equals to number of pixel categories, e.g. 21 for PASCAL VOC 2012, denoted as “1 conv”.
- One more 512-channel convolution can be added at the middle as well, denoted as “2 conv”.
5. Image Classification Results

- Model A, with input 224×224, B1 removed, only depth of 38, it got 19.2% and 4.7% top-1 and top-5 errors respectively, outperforms ResNet, Inception-v4 and Inception-ResNet-v2.
6. Semantic Segmentation Results
6.1. PASCAL VOC

- Model A with “1 conv”: 78.76% mIoU.
- Model A with “2 conv”: 80.84% mIoU.
- They both outperform ResNet-101 and ResNet-152 by large margin.

- Model A with “2 conv”: 82.5% mIoU, outperforms SOTA methods like FCN, CRF-RNN, DeconvNet, and DeepLabv2.
6.2. Cityscapes & ADE20K

- Model A2, initialize it using weights from Model A, and tune it with the Places 365 dataset, with “2 conv”: It performs the best.

- Model A2 outperforms SOTA like DilatedNet and DeepLabv2.
- In the final journal version, it also got comparable results with PSPNet and DeepLabv3.
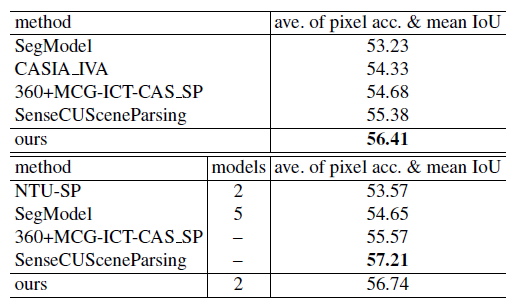
- Here, multi-scale testing, model averaging, post-processing with CRFs are used. Again, Model A2 performs the best.
6.3. PASCAL-Context
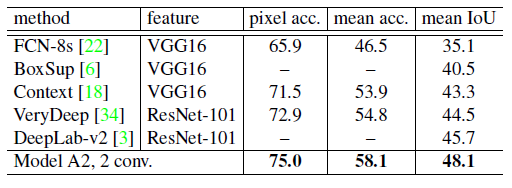
- Model A2 with “2 conv” got 48.1% mIoU, outperforms DeepLabv2 by large margin.
6.4. Visualizations


- There are still many visualizations for other datasets, please feel free to read the paper.
Reference
[2019 JPR] [ResNet-38]
Wider or Deeper: Revisiting the ResNet Model for Visual Recognition
My Previous Reviews
Image Classification [LeNet] [AlexNet] [Maxout] [NIN] [ZFNet] [VGGNet] [Highway] [SPPNet] [PReLU-Net] [STN] [DeepImage] [SqueezeNet] [GoogLeNet / Inception-v1] [BN-Inception / Inception-v2] [Inception-v3] [Inception-v4] [Xception] [MobileNetV1] [ResNet] [Pre-Activation ResNet] [RiR] [RoR] [Stochastic Depth] [WRN] [ResNet-38] [Shake-Shake] [FractalNet] [Trimps-Soushen] [PolyNet] [ResNeXt] [DenseNet] [PyramidNet] [DRN] [DPN] [Residual Attention Network] [DMRNet / DFN-MR] [IGCNet / IGCV1] [MSDNet] [ShuffleNet V1] [SENet] [NASNet] [MobileNetV2]
Object Detection [OverFeat] [R-CNN] [Fast R-CNN] [Faster R-CNN] [MR-CNN & S-CNN] [DeepID-Net] [CRAFT] [R-FCN] [ION] [MultiPathNet] [NoC] [Hikvision] [GBD-Net / GBD-v1 & GBD-v2] [G-RMI] [TDM] [SSD] [DSSD] [YOLOv1] [YOLOv2 / YOLO9000] [YOLOv3] [FPN] [RetinaNet] [DCN]
Semantic Segmentation [FCN] [DeconvNet] [DeepLabv1 & DeepLabv2] [CRF-RNN] [SegNet] [ParseNet] [DilatedNet] [DRN] [RefineNet] [GCN] [PSPNet] [DeepLabv3] [ResNet-38] [LC] [FC-DenseNet] [IDW-CNN] [DIS] [SDN]
Biomedical Image Segmentation [CUMedVision1] [CUMedVision2 / DCAN] [U-Net] [CFS-FCN] [U-Net+ResNet] [MultiChannel] [V-Net] [3D U-Net] [M²FCN] [SA] [QSA+QNT] [3D U-Net+ResNet]
Instance Segmentation [SDS] [Hypercolumn] [DeepMask] [SharpMask] [MultiPathNet] [MNC] [InstanceFCN] [FCIS]
Super Resolution [SRCNN] [FSRCNN] [VDSR] [ESPCN] [RED-Net] [DRCN] [DRRN] [LapSRN & MS-LapSRN] [SRDenseNet]
Human Pose Estimation [DeepPose] [Tompson NIPS’14] [Tompson CVPR’15] [CPM]
Codec Post-Processing [ARCNN] [Lin DCC’16] [IFCNN] [Li ICME’17] [VRCNN] [DCAD] [DS-CNN]
