Review: Inception-v3 — 1st Runner Up (Image Classification) in ILSVRC 2015
In this story, Inception-v3 [1] is reviewed. By rethinking the inception architecture, computational efficiency and fewer parameters are realized. With fewer parameters, 42-layer deep learning network, with similar complexity as VGGNet, can be achieved.
AlexNet [2]: 60 million parameters
VGGNet [3]: 3× more parameters than AlexNet
GoogLeNet / Inception-v1 [4]: 7 million parameters
With 42 layers, lower error rate is obtained and make it become the 1st Runner Up for image classification in ILSVRC (ImageNet Large Scale Visual Recognition Competition) 2015. And it is a 2016 CVPR paper with about 2000 citations when I was writing this story. (Sik-Ho Tsang @ Medium)

ImageNet, is a dataset of over 15 millions labeled high-resolution images with around 22,000 categories. ILSVRC uses a subset of ImageNet of around 1000 images in each of 1000 categories. In all, there are roughly 1.2 million training images, 50,000 validation images and 100,000 testing images.
About The Inception Versions
There are 4 versions. The first GoogLeNet must be the Inception-v1 [4], but there are numerous typos in Inception-v3 [1] which lead to wrong descriptions about Inception versions. These maybe due to the intense ILSVRC competition at that moment. Consequently, there are many reviews in the internet mixing up between v2 and v3. Some of the reviews even think that v2 and v3 are the same with only some minor different settings.
Nevertheless, in Inception-v4 [5], Google has a much more clear description about the version issue:
“The Inception deep convolutional architecture was introduced as GoogLeNet in (Szegedy et al. 2015a), here named Inception-v1. Later the Inception architecture was refined in various ways, first by the introduction of batch normalization (Ioffe and Szegedy 2015) (Inception-v2). Later by additional factorization ideas in the third iteration (Szegedy et al. 2015b) which will be referred to as Inception-v3 in this report.”
Thus, the BN-Inception / Inception-v2 [6] is talking about batch normalization while Inception-v3 [1] is talking about factorization ideas.
What are covered:
- Factorizing Convolutions
- Auxiliary Classifiers
- Efficient Grid Size Reduction
- Inception-v3 Architecture
- Label Smoothing As Regularization
- Ablation Study
- Comparison with State-of-the-art Approaches
1. Factorizing Convolutions
The aim of factorizing Convolutions is to reduce the number of connections/parameters without decreasing the network efficiency.
1.1. Factorization Into Smaller Convolutions
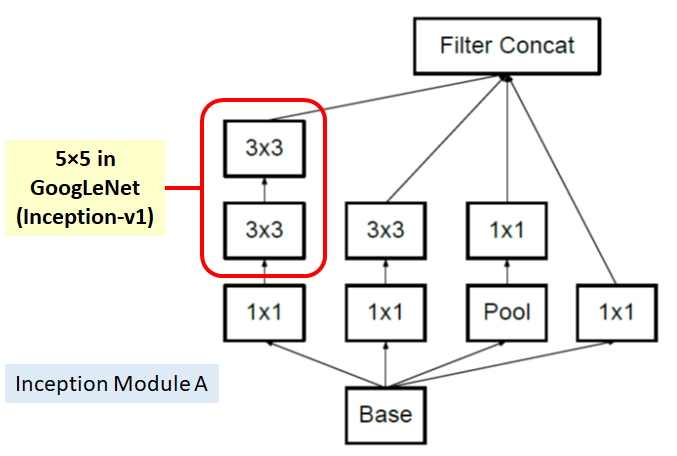
Two 3×3 convolutions replaces one 5×5 convolution as follows:

By using 1 layer of 5×5 filter, number of parameters = 5×5=25
By using 2 layers of 3×3 filters, number of parameters = 3×3+3×3=18
Number of parameters is reduced by 28%
Similar technique has been mentioned in VGGNet [3] already.
With this technique, one of the new Inception modules (I call it Inception Module A here) becomes:
1.2. Factorization Into Asymmetric Convolutions
One 3×1 convolution followed by one 1×3 convolution replaces one 3×3 convolution as follows:
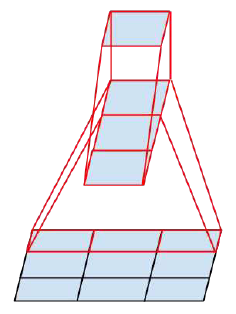
By using 3×3 filter, number of parameters = 3×3=9
By using 3×1 and 1×3 filters, number of parameters = 3×1+1×3=6
Number of parameters is reduced by 33%
You may ask why we don’t use two 2×2 filters to replace one 3×3 filter?
If we use two 2×2 filters, number of parameters = 2×2×2=8
Number of parameters is only reduced by 11%
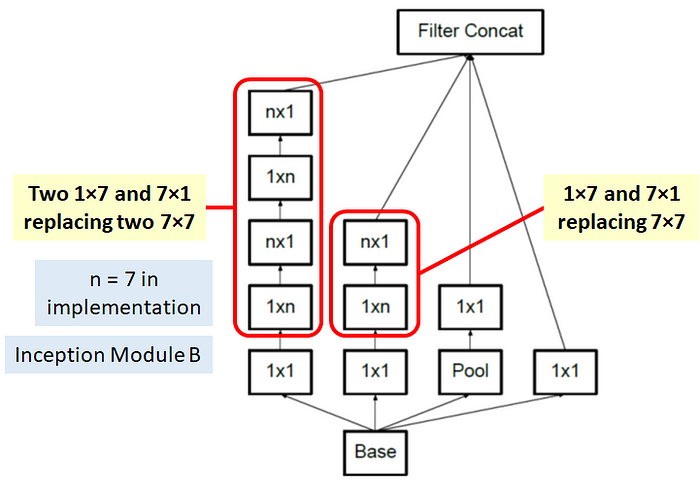
With this technique, one of the new Inception modules (I call it Inception Module B here) becomes:
And Inception module C is also proposed for promoting high dimensional representations according to author descriptions as follows:
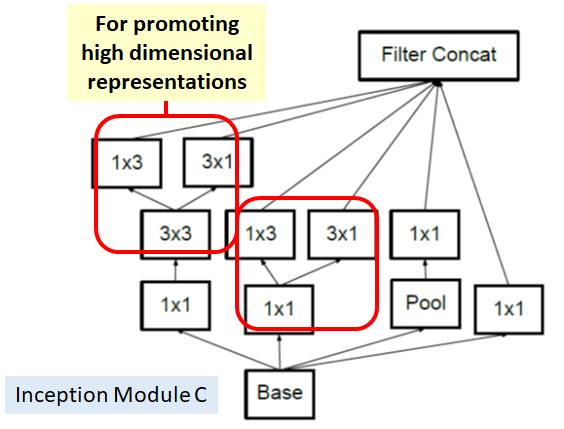
Thus, authors suggest these 3 kinds of Inception Modules. With factorization, number of parameters is reduced for the whole network, it is less likely to be overfitting, and consequently, the network can go deeper!
2. Auxiliary Classifier
Auxiliary Classifiers were already suggested in GoogLeNet / Inception-v1 [4]. There are some modifications in Inception-v3.
Only 1 auxiliary classifier is used on the top of the last 17×17 layer, instead of using 2 auxiliary classifiers. (The overall architecture would be shown later.)

The purpose is also different. In GoogLeNet / Inception-v1 [4], auxiliary classifiers are used for having deeper network. In Inception-v3, auxiliary classifier is used as regularizer. So, actually, in deep learning, the modules are still quite intuitive.
Batch normalization, suggested in Inception-v2 [6], is also used in the auxiliary classifier.
3. Efficient Grid Size Reduction
Conventionally, such as AlexNet and VGGNet, the feature map downsizing is done by max pooling. But the drawback is either too greedy by max pooling followed by conv layer, or too expensive by conv layer followed by max pooling. Here, an efficient grid size reduction is proposed as follows:

With the efficient grid size reduction, 320 feature maps are done by conv with stride 2. 320 feature maps are obtained by max pooling. And these 2 sets of feature maps are concatenated as 640 feature maps and go to the next level of inception module.
Less expensive and still efficient network is achieved by this efficient grid size reduction.
4. Inception-v3 Architecture
There are some typos for the architecture in the passage and table within the paper. I believe this is due to the intense ILSVRC competition in 2015. I thereby look into the codes to realize the architecture:

With 42 layers deep, the computation cost is only about 2.5 higher than that of GoogLeNet [4], and much more efficient than that of VGGNet [3].
The links I use for reference about the architecture:
PyTorch version of Inception-v3:
https://github.com/pytorch/vision/blob/master/torchvision/models/inception.py
Inception-v3 on Google Cloud
https://cloud.google.com/tpu/docs/inception-v3-advanced
5. Label Smoothing As Regularization
The purpose of label smoothing is to prevent the largest logit from becoming much larger than all others:
new_labels = (1 — ε) * one_hot_labels + ε / Kwhere ε is 0.1 which is a hyperparameter and K is 1000 which is the number of classes. A kind of dropout effect observed in classifier layer.
6. Ablation Study

Using single-model single-crop, we can see the top-1 error rate is improved when proposed techniques are added on top of each other:
Inception-v1: 29%
Inception-v2: 25.2%
Inception-v3: 23.4%
+ RMSProp: 23.1%
+ Label Smoothing: 22.8%
+ 7×7 Factorization: 21.6%
+ Auxiliary Classifier: 21.2% (With top-5 error rate of 5.6%)
where 7×7 Factorization is to factorize the first 7×7 conv layer into three 3×3 conv layer.
7. Comparison with State-of-the-art Approaches

With single-model multi-crop, Inception-v3 with 144 crops obtains top-5 error rate is 4.2%, which outperforms PReLU-Net and Inception-v2 which were published in 2015.
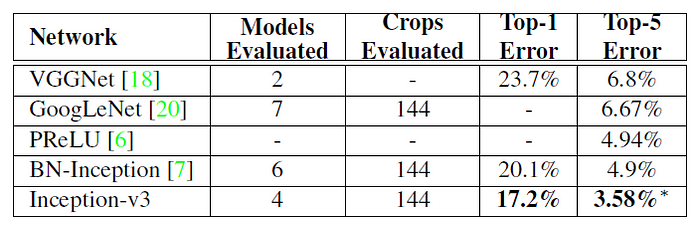
With multi-model multi-crop, Inception-v3 with 144 crops and 4 models ensembled, the top-5 error rate of 3.58% is obtained, and finally obtained 1st Runner Up (image classification) in ILSVRC 2015, while the winner is ResNet [7] which will be reviewed later. Of course, Inception-v4 [5] will also be reviewed later on as well.
References
- [2016 CVPR] [Inception-v3]
Rethinking the Inception Architecture for Computer Vision - [2012 NIPS] [AlexNet]
ImageNet Classification with Deep Convolutional Neural Networks - [2015 ICLR] [VGGNet]
Very Deep Convolutional Networks for Large-Scale Image Recognition - [2015 CVPR] [GoogLeNet / Inception-v1]
Going Deeper with Convolutions - [2017 AAAI] [Inception-v4]
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning - [2015 ICML] [BN-Inception / Inception-v2]
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift - [2016 CVPR] [ResNet]
Deep Residual Learning for Image Recognition
My Reviews
- Review: Batch Normalization (Inception-v2 / BN-Inception) -The 2nd to Surpass Human-Level Performance in ILSVRC 2015 (Image Classification)
- Review: PReLU-Net, The First to Surpass Human-Level Performance in ILSVRC 2015 (Image Classification)
- Review: GoogLeNet (Inception v1) — Winner of ILSVRC 2014 (Image Classification)
- Review: VGGNet — 1st Runner-Up (Image Classification), Winner (Localization) in ILSVRC 2014
- Review of AlexNet, CaffeNet — Winner of ILSVRC 2012 (Image Classification)
