Review: Panoptic Segmentation
A Kind of Combination of Semantic Segmentation and Instance Segmentation

Panoptic Segmentation
PS, by Facebook AI Research (FAIR), and Heidelberg University
2019 CVPR, Over 600 Citations (Sik-Ho Tsang @ Medium)
Panoptic Segmentation, Semantic Segmentation, Instance Segmentation
- Panoptic Segmentation (PS) unifies the typically distinct tasks of semantic segmentation (assign a class label to each pixel) and instance segmentation (detect and segment each object instance).
- A novel panoptic quality (PQ) metric is proposed to capture performance for all classes (stuff and things) in an interpretable and unified manner.
- The aim is to revive the interest of the community in a more unified view of image segmentation.
Outline
- What is Panoptic Segmentation (PS)?
- Panoptic Quality (PQ) Metric
- Experimental Results
1. What is Panoptic Segmentation (PS)?

- Things: countable objects such as people, animals, and tools.
- Stuffs: amorphous regions of similar texture or material such as grass, sky, and road.
- The PS task:
- encompasses both stuff and thing classes;
- uses a simple but general format; and
- introduces a uniform evaluation metric for all classes.
Panoptic segmentation generalizes both semantic and instance segmentation and it is expected that the unified task will present novel challenges and enable innovative new methods.
2. Panoptic Quality (PQ) Metric

- It involves two steps: (1) segment matching and (2) PQ computation given the matches.
2.1. Segment Matching
- A predicted segment and a ground truth segment can match only if their intersection over union (IoU) is strictly greater than 0.5.
- This requirement, together with the non-overlapping property of a panoptic segmentation, gives a unique matching: there can be at most one predicted segment matched with each ground truth segment.
- Due to the uniqueness property, for IoU>0.5, any reasonable matching strategy (including greedy and optimal) will yield an identical matching.
- Lower thresholds are unnecessary as matches with IoU≤0.5 are rare in practice.
A toy example is shown above: Pairs of segments of the same color have IoU larger than 0.5 and are therefore matched. The figure shows how the segments for the person class are partitioned into true positives TP, false negatives FN, and false positives FP.
2.2. PQ Computation
- For each class, the unique matching splits the predicted and ground truth segments into three sets: true positives (TP), false positives (FP), and false negatives (FN), representing matched pairs of segments, unmatched predicted segments, and unmatched ground truth segments, respectively.
- PQ is defined as:
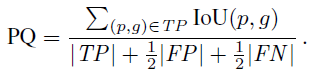
- where:
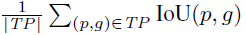
- is simply the average IoU of matched segments, while.
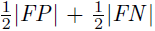
- is added to the denominator to penalize segments without matches.
- If PQ is multiplied and divided by the size of the TP set, then PQ can be seen as the multiplication of a segmentation quality (SQ) term and a recognition quality (RQ) term:
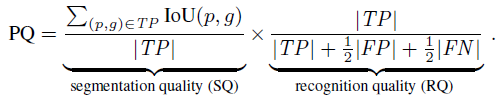
RQ is the familiar F1 score widely used for quality estimation in detection settings. SQ is simply the average IoU of matched segments.
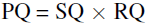
- The above decomposition provides further insight for analysis.
2.3. Post-Processing NMS
- To measure PQ, we must first resolve these overlaps. A simple non-maximum suppression (NMS)-like procedure is performed.
- We first sort the predicted segments by their confidence scores and remove instances with low scores.
- Then, we iterate over sorted instances, starting from the most confident.
- For each instance we first remove pixels which have been assigned to previous segments, then, if a sufficient fraction of the segment remains, we accept the non-overlapping portion, otherwise we discard the entire segment.
- (There are also other details such as void labels when matching and calculating PQ. Please feel free to read the paper.)
3. Experimental Results
3.1. PQ for Thing

- Some SOTA approaches such as Mask R-CNN and G-RMI are evaluated.
- AP^NO: AP of the non-overlapping predictions.
- Removing overlaps harms AP as detectors benefit from predicting multiple overlapping hypotheses.
Methods with better AP also have better AP^NO and likewise improved PQ.
3.2. PQ for Stuff
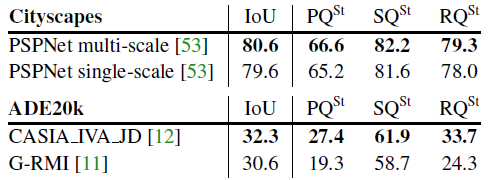
Methods with better mean IoU also show better PQ results.
3.3. Overall PQ
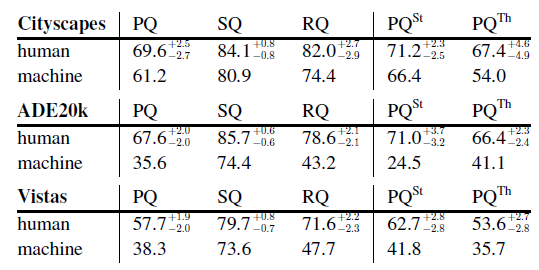
- For SQ, machines trail humans only slightly.
- On the other hand, machine RQ is dramatically lower than human RQ, especially on ADE20k and Vistas.
This implies that recognition, i.e., classification, is the main challenge for current methods. Overall, there is a significant gap between human and machine performance.
3.4. Visualization

- Visualizations of panoptic outputs are shown above.
Panoptic segmentation is a kind of combination of semantic segmentation and instance segmentation.
The main purpose of this story is to introduce the PQ, SQ and RQ metrics.
Reference
[2019 CVPR] [PS]
Panoptic Segmentation
Panoptic Segmentation
2019 [PS]
