Review: PyramidNet — Deep Pyramidal Residual Networks (Image Classification)
Gradually Increasing the Feature Map Dimensions, New Positions of ReLU and BN, Better Than DenseNet.
In this story, PyramidNet, by KAIST, is shortly reviewed. It is found that by gradually increasing the feature map dimensions, instead of increasing the feature map dimensions sharply, the classification accuracy is improved. In addition, new positions of ReLU and BN (Batch Norm) within a residual building block are also suggested.
Since it enhances ResNet and Pre-Activation ResNet, it is better to know about them before reading PyramidNet. (If interested, please read my reviews about them.) It is published in 2017 CVPR with more than 100 citations. (Sik-Ho Tsang @ Medium)
Outline
- Additive PyramidNet and Multiplicative PyramidNet
- New Positions of ReLU and BN
- Comparison with State-of-the-art Approaches
1. Gradually Increasing the Feature Map Dimensions
1.1. Original ResNet

- In many CNN architectures, feature map dimensions are not increased until they encounter a layer with downsampling.
- Particularly in original ResNet, as the equation above, if n(k) ∈ {1, 2, 3, 4} denotes the index of the group to which the k-th residual unit belongs. The residual units that belong to the same group have an equal feature map size, and the n-th group contains N_n residual units.
1.2. Additive PyramidNet and Multiplicative PyramidNet

- PyramidNet suggests to gradually increasing the feature map dimensions. Two forms of PyramidNet, Additive PyramidNet and Multiplicative PyramidNet are proposed as above. It is found that Additive PyramidNet is better than Multiplicative PyramidNet.

- The above table is the Additive PyramidNet architecture used for benchmarking with CIFAR-10 and CIFAR-100.

- (a): Basic residual units in original ResNet.
- (b):Bottleneck residual units in original ResNet.
- (c): Wide residual units in WRN.
- (d): Pyramid residual units.
- (e): Pyramid bottleneck residual units.
- We can see that (d) and (e) gradually increasing the feature map dimensions.

- As shown above, by comparing 110-layer PyramidNet-110 (α = 48) with Pre-Activation ResNet-110, PyramidNet can obtain lower test error.
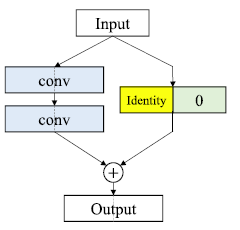
- As the feature map dimension is increasing, we need to match the feature map dimensions of input and output. It is found that zero-padded shortcut connection is normally good enough compared with other types of shortcut connections such as projection shortcut.
2. New Positions of ReLU and BN

- (a): The authors in Pre-Activation ResNet have already tried different orders of Conv, ReLU and BN, and finally come up with BN-ReLU-Conv structure.
- (b): Here, more combinations are tried. Simply removing the first ReLU of Pre-Activation ResNet, leads to a small performance improvement.
- (c): Simply adding the BN at the end of Pre-Activation ResNet, leads to a small performance improvement. It is found to be better to have BN before going to the next residual unit.
- (d): By combining (b) and (c), we can come up the structure in (d).

- As shown above, (d) has the lowest error rate on CIFAR-10 and CIFAR-100.
3. Comparison with State-of-the-art Approaches
3.1. CIFAR-10 and CIFAR-100

- The above are all Additive PyramidNets.
- PyramidNet (α = 48): With only 1.7M #parameters, 4.58% and 23.12% error rates are obtained on CIFAR-10 and CIFAR-100 respectively.
- PyramidNet (bottleneck, α = 200): With 26M #parameters, similar to the famous DenseNet-BC, 3.31% and 16.35% error rates are obtained on CIFAR-10 and CIFAR-100 respectively, which outperforms the famous DenseNet.
3.2. ILSVRC 2012 Validation Set

- PyramidNet-200 (α = 300): It is already better than Inception-ResNet-v2 proposed by Inception-v4.
- PyramidNet-200 (α = 450)*: It is even better.
- However, they did not compare with DenseNet here.
Reference
[2017 CVPR] [PyramidNet]
Deep Pyramidal Residual Networks
My Related Reviews
Image Classification
[LeNet] [AlexNet] [ZFNet] [VGGNet] [SPPNet] [PReLU-Net] [DeepImage] [GoogLeNet / Inception-v1] [BN-Inception / Inception-v2] [Inception-v3] [Inception-v4] [Xception] [MobileNetV1] [ResNet] [Pre-Activation ResNet] [RiR] [RoR] [Stochastic Depth] [WRN] [FractalNet] [Trimps-Soushen] [PolyNet] [ResNeXt] [DenseNet]
Object Detection
[OverFeat] [R-CNN] [Fast R-CNN] [Faster R-CNN] [DeepID-Net] [R-FCN] [ION] [MultiPathNet] [NoC] [G-RMI] [TDM] [SSD] [DSSD] [YOLOv1] [YOLOv2 / YOLO9000] [FPN] [RetinaNet]
Semantic Segmentation
[FCN] [DeconvNet] [DeepLabv1 & DeepLabv2] [ParseNet] [DilatedNet] [PSPNet] [DeepLabv3]
Biomedical Image Segmentation
[CUMedVision1] [CUMedVision2 / DCAN] [U-Net] [CFS-FCN] [U-Net+ResNet]
Instance Segmentation
[DeepMask] [SharpMask] [MultiPathNet] [MNC] [InstanceFCN] [FCIS]
