Review — Show and Tell: A Neural Image Caption Generator
Neural Image Caption (NIC) for Caption Generation
4 min readOct 14, 2021

In this story, Show and Tell: A Neural Image Caption Generator, by Google, is reviewed. In this paper:
- Neural Image Caption (NIC) is designed for image captioning.
- BN-Inception / Inception-v2 generates the image representation.
- LSTM generates natural sentences describing the image.
This is a paper in 2015 CVPR with over 5000 citations. (Sik-Ho Tsang @ Medium)
Outline
- Neural Image Caption (NIC) Network Architecture
- Experimental Results
1. Neural Image Caption (NIC) Network Architecture

1.1. Objective
- NIC is to directly maximize the probability of the correct description given the image:

- where θ are the parameters of our model, I is an image, and S its correct transcription.
- Since S represents any sentence, its length is unbounded. Thus, it is common to apply the chain rule to model the joint probability over S0, …, SN, where N is the length of this particular example as:

1.2. LSTM as RNN
- It is natural to model p(St|I, S0, …, St-1) with a Recurrent Neural Network (RNN).

- where xt and ht are the input and the hidden state at time t.
- f is LSTM as it can obtain SOTA performance on sequence tasks.
The core ability of LSTM is to either keep a value from the gated layer if the gate is 1 or zero this value if the gate is 0.
1.3. BN-Inception / Inception-v2 as CNN
The particular choice of CNN is BN-Inception / Inception-v2 which yields the good performance on the ILSVRC 2014 classification competition.
1.4. Overview

- Each word is represented as a one-hot vector St of dimension equal to the size of the dictionary.
- S0 is a special start word and SN is a special stop word.
- The image I is only input once, at t=-1.
1.5. Training
- During training, the loss is the sum of the negative log likelihood of the correct word at each step as follows:
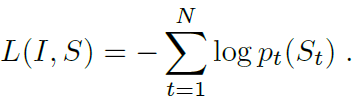
- CNN is initialized by pre-trained ImageNet, and left unchanged.
- We is randomly initialized, since initializing using large corpus has no significant gain.
1.6. Inference
- During inference, BeamSearch is used which iteratively considers the set of the k best sentences up to time t as candidates to generate sentences of size t+1, and keep only the resulting best k of them.
- A beam of size 20 is used . Using a beam size of 1 (i.e., greedy search) did degrade our results by 2 BLEU points on average.
2. Experimental Results
2.1. Datasets

- With the exception of SBU, each image has been annotated by labelers with 5 sentences that are relatively visual and unbiased.
- SBU consists of descriptions given by image owners when they uploaded them to Flickr.
2.2. BLEU

- Human scores were computed by comparing one of the human captions against the other four.
NIC outperforms SOTA approaches such as m-RNN by large margin.
- Transfer learning is tried, but when running the MSCOCO model on SBU, our performance degrades from 28 down to 16.
2.3. Sentence Diversity

- If the best candidate is taken, the sentence is present in the training set 80% of the times.
2.4. Qualitative Results


Reference
[2015 CVPR] [Show and Tell/NIC]
Show and Tell: A Neural Image Caption Generator
Natural Language Processing (NLP)
Machine Translation
2014 [Seq2Seq] [RNN Encoder-Decoder]
Image Captioning
2015 [m-RNN] [R-CNN+BRNN] [Show and Tell/NIC]
