Brief Review — Improving Neural Machine Translation Models with Monolingual Data
Back Translation, Translate Monolingual Target Data Back to Source Data, as Additional Training Data

Improving Neural Machine Translation Models with Monolingual Data,
Back Translation, by University of Edinburgh
2016 ACL, Over 1900 Citations (Sik-Ho Tsang @ Medium)
Natural Language Processing, NLP, Neural Machine Translation, NMT
- By pairing monolingual training data with an automatic backtranslation, it can be treated as additional parallel training data to obtain substantial improvements.
Outline
- Back Translation
- Results
1. Back Translation
- The overall training procedures are as follows:
- First, NMT is trained using paired training data.
- Then, with trained NMT, back-translation can be performed, i.e. an automatic translation of the monolingual target text into the source language. Additional synthetic parallel data is obtained.
- During further training, synthetic parallel data is mixed into the original (human-translated) parallel data for training.
- The network used is Attention Decoder/RNNSearch.
2. Results
2.1. English→German WMT 15

- After training the baseline model using real parallel data, synthetic parallel data is obtained by back-translating a random sample of 3,600,000 sentences from the German monolingual data set into English, for further training.
Including synthetic data during training is very effective, and yields an improvement over the baseline by 2.8–3.4 BLEU.
2.2. German→English WMT 15

- For German→English, 4,200,000 monolingual English sentences are back-translated into German.
There are substantial improvements (3.6–3.7 BLEU) by adding monolingual training data with synthetic source sentences.
2.3. Turkish→English IWSLT 14

- To obtain a synthetic parallel training set, a random sample of 3,200,000 sentences from Gigaword, is back-translated.
With synthetic training data (Gigawordsynth), back translation outperform the baseline by 2.7 BLEU on average.
2.4. Training Curves Analysis
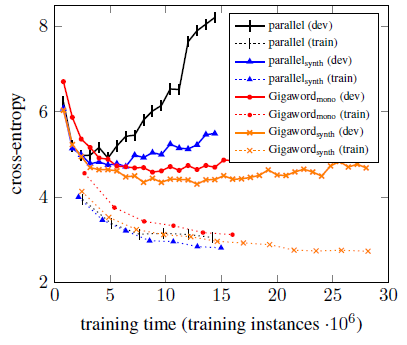
- Model trained on only parallel training data quickly overfits.
All three monolingual data sets (parallelsynth, Gigawordmono, or Gigawordsynth) delay overfitting, and give better perplexity on the development set.
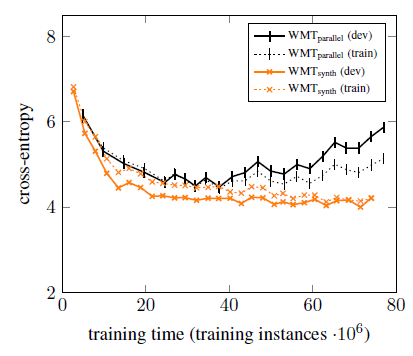
- Since more training data is available for English→German, there is no indication that overfitting happens during the first 40 million training instances (or 7 days of training).
The system with synthetic data reaches a lower cross-entropy on the development set.
With back-translation, additional training set can be obtained from monolingual data.
Reference
[2016 ACL] [Back Translation]
Improving Neural Machine Translation Models with Monolingual Data
4.2. Machine Translation
2014 … 2016 [Back Translation] … 2020 [Batch Augment, BA] [GPT-3] [T5] [Pre-LN Transformer] [OpenNMT] 2021 [ResMLP] [GPKD]
