Review — GPT-3: Language Models are Few-Shot Learners
GPT-3: 175B-Large Model
Language Models are Few-Shot Learners
GPT-3, by OpenAI
2020 NeurIPS, Over 3000 Citations (Sik-Ho Tsang @ Medium)
Language Model, Natural Language Processing, NLP, Transformer, GPT, GPT-2
- Scaling up language models greatly improves task-agnostic, few-shot performance.
- Specifically GPT-3, an autoregressive language model, is trained, with 175 billion (175B) parameters, 10× more than any previous non-sparse language model.
- GPT-3 is applied without any gradient updates (zero-shot), or fine-tuning with one-shot and few-shot demonstrations specified purely via text interaction with the model.
- (It got 75 pages in arXiv, I only select some points to present.)
Outline
- GPT-3 Model Variants
- GPT-3 Training
- GPT-3 Approach
- GPT-3 Evaluation Results
1. GPT-3 Model Variants

- The same model and architecture as GPT-2 is used, with the exception that alternating dense and locally banded sparse attention patterns are used in the layers of the Transformer, similar to the Sparse Transformer.
- 8 different sizes of model are trained, ranging over three orders of magnitude from 125 million (125M) parameters to 175 billion (175B) parameters, with the last being the model called GPT-3.
- All models use a context window of nctx=2048 tokens.
2. GPT-3 Training
2.1. Dataset

- Common Crawl dataset, constituting nearly a trillion words, is used.
- It is downloaded and filtered based on similarity to a range of high-quality reference corpora;
- Then, fuzzy deduplication is performed at the document level;
- Finally, known high-quality reference corpora are added to the training mix to augment CommonCrawl and increase its diversity: including an expanded version of the WebText dataset, two internet-based books corpora (Books1 and Books2) and English-language Wikipedia.
2.1. Training Computation

- To train the larger models without running out of memory, a mixture of model parallelism within each matrix multiply and model parallelism across the layers of the network are used.
- All models were trained on V100 GPU’s on part of a high-bandwidth cluster provided by Microsoft.
- Training the GPT-3 175B consumed several thousand petaflop/s-days of compute during pre-training, compared to tens of petaflop/s-days for a 1.5B parameter GPT-2 model.
3. GPT-3 Approach

- The basic pre-training approach, including model, data, and training, is similar to the process described in GPT-2, with relatively straightforward scaling up of the model size, dataset size and diversity, and length of training.
3.1. Fine-Tuning (FT)
- The most common approach appeared in recent years, which involves updating the weights of a pre-trained model by training on a supervised dataset specific to the desired task.
- In this work, GPT-3 is NOT fine-tuned.
3.2. Few-Shot (FS)
- The model is given a few demonstrations of the task at inference time as conditioning, but no weight updates are allowed.
- The main advantages of few-shot are a major reduction in the need for task-specific data and reduced potential to learn an overly narrow distribution from a large but narrow fine-tuning dataset.
- A small amount of task specific data is still required.
3.3. One-Shot (1S)
- It is the same as few-shot except that only one demonstration is allowed.
- The reason to distinguish one-shot from few-shot and zero-shot (below) is that it most closely matches the way in which some tasks are communicated to humans.
- Also, it is sometimes difficult to communicate the content or format of a task if no examples are given.
3.4. Zero-Shot (0S)
- It is the same as one-shot except that no demonstrations are allowed, and the model is only given a natural language instruction describing the task.
- This method provides maximum convenience, but is also the most challenging.
- In some cases it may even be difficult for humans to understand the format of the task without prior examples, so this setting is in some cases “unfairly hard”. Nevertheless, for at least some settings zero-shot is closest to how humans perform tasks — for example, in the translation example, a human would likely know what to do from just the text instruction.
In this paper, GPT-3 focuses on zero-shot, one-shot and few-shot.
4. GPT-3 Evaluation Results
4.1. 42 Downstream Tasks

- K: The number of demonstration examples.
- A simple task is learnt which requiring the model to remove extraneous symbols from a word.
Though the results in this case are particularly striking, the general trends with both model size and number of examples in-context hold for most tasks.
- These “learning” curves involve no gradient updates or fine-tuning, just increasing numbers of demonstrations given as conditioning.
The steeper “in-context learning curves” for large models demonstrate improved ability to learn a task from contextual information.
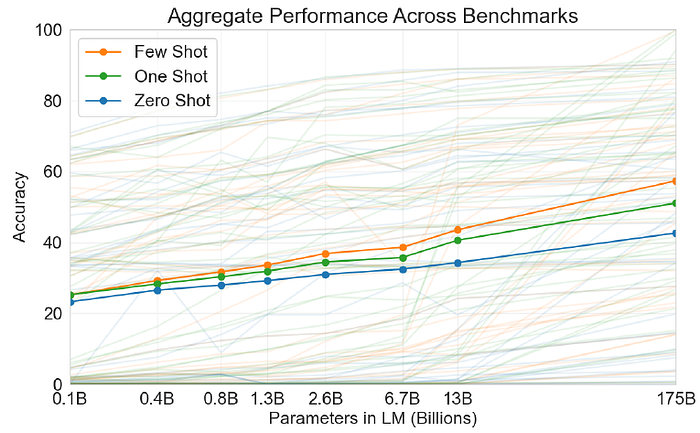
- There are 42 downstream tasks.
While zero-shot performance improves steadily with model size, few-shot performance increases more rapidly, demonstrating that larger models are more proficient at in-context learning.
- Some tasks on which few-shot performance struggles, even at the scale of GPT-3.
4.2. Machine Translation
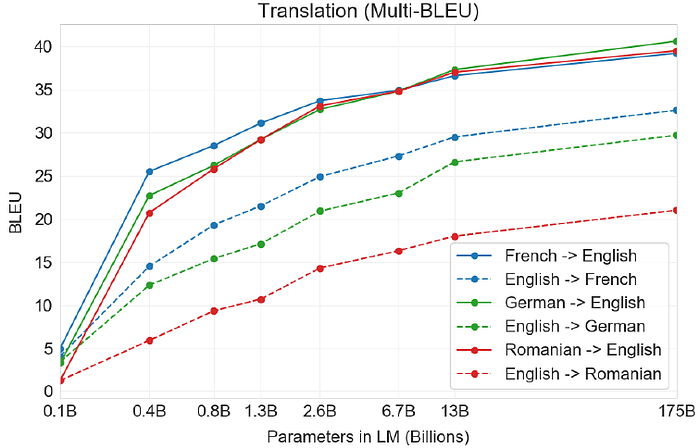
- There is a consistent trend of improvement across all datasets as the model scales, and as well as tendency for translation into English to be stronger than translation from English.
The above figures only summarize some findings for accuracy-metric datasets. There are still other results, e.g.: non-accuracy-metric dataset evaluations. Please feel free to read the paper directly.
Reference
[2020 NeurIPS] [GPT-3]
Language Models are Few-Shot Learners
Natural Language Processing (NLP)
Language/Sequence Model: 2007 [Bengio TNN’07] 2013 [Word2Vec] [NCE] [Negative Sampling] 2014 [GloVe] [GRU] [Doc2Vec] 2015 [Skip-Thought] 2016 [GCNN/GLU] [context2vec] [Jozefowicz arXiv’16] [LSTM-Char-CNN] 2017 [TagLM] [CoVe] [MoE] 2018 [GLUE] [T-DMCA] [GPT] [ELMo] 2019 [T64] [Transformer-XL] [BERT] [RoBERTa] [GPT-2] [DistilBERT] [MT-DNN] 2020 [ALBERT] [GPT-3]
