Brief Review — PubMedBERT: Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing
PubMedBERT Pretraining BERT From Scratch Using Specific Domain Corpus

Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing,
PubMedBERT, by Microsoft Research
2022 ACM T HEALTH, Over 1000 Citations (Sik-Ho Tsang @ Medium)Medical NLP/LLM
2017 [LiveQA] 2018 [Clinical NLP Overview] 2019 [MedicationQA] [G-BERT] [PubMedQA] 2020 [BioBERT] [BEHRT] 2021 [MedGPT] [Med-BERT] [MedQA] 2023 [Med-PaLM]
==== My Other Paper Readings Are Also Over Here ====
- For specific-domains with abundant unlabeled text, such as biomedicine, pretraining language models from scratch results in substantial gains over continual pretraining of general-domain language models.
- Biomedical Language Understanding & Reasoning Benchmark (BLURB) is proposed for specific-domain pretraining.
Outline
- PubMedBERT
- Results
1. PubMedBERT
1.1. Domain-Specific Pretraining

It is shown that domain-specific pretraining from scratch substantially outperforms continual pretraining of generic language models, thus demonstrating that the prevailing assumption in support of mixed-domain pretraining is not always applicable.
1.2. Model
BERT is used.
- Whole-word masking (WWM) enforces that the whole word must be masked for Masked Language Model (MLM).
1.3. BLURB Dataset

- To the best of authors’ knowledge, BLUE [45] is the first attempt to create an NLP benchmark in the biomedical domain. But BLUE has limited coverage.
Biomedical Language Understanding & Reasoning Benchmark (BLURB) is proposed which focuses on PubMed-based biomedical applications.
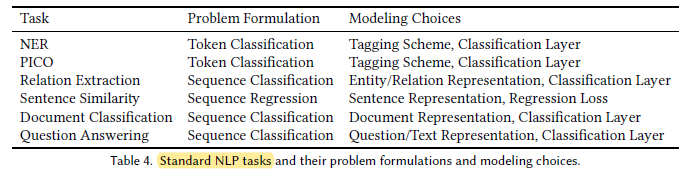
- (Please read the paper for more details.)
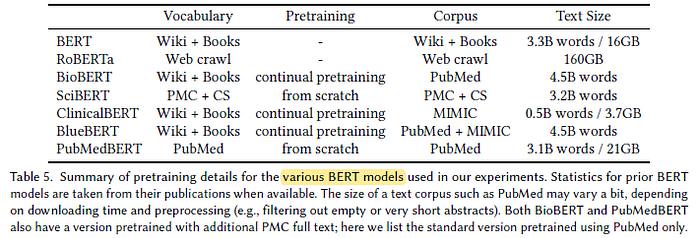
PubMedBERT uses much larger specific-domain corpus (21GB).
2. Results

PubMedBERT consistently outperforms all the other BERT models in most biomedical NLP tasks, often by a significant margin.
