Brief Review — SpecAugment on Large Scale Datasets
SpecAugment With Adaptive Time Masking

SpecAugment on Large Scale Datasets
SpecAugment & Adaptive Masking, by Google Inc.
2020 ICASSP, Over 140 Citations (Sik-Ho Tsang @ Medium)Acoustic Model / Automatic Speech Recognition (ASR) / Speech-to-Text (STT)
1991 … 2019 [SpecAugment] [Cnv Cxt Tsf] 2020 [FAIRSEQ S2T] [PANNs] [Conformer]
==== My Other Paper Readings Are Also Over Here ====
- Improvement is observed across all test domains by mixing raw training data augmented with SpecAugment and noise-perturbed training data when training the acoustic model.
- A modification of SpecAugment is also introduced that adapts the time mask size and/or multiplicity depending on the length of the utterance, which can potentially benefit large scale tasks.
Outline
- SpecAugment & Adaptive Masking
- Results
1. SpecAugment & Adaptive Masking
1.1. SpecAugment: Three Basic Augmentations
- SpecAugment policy is obtained by composing 3 basic augmentations — time warping, frequency masking and time masking.
- The time and frequency dimensions of the spectrogram are denoted as τ and ν.
- (1) Time warping with parameter W: A displacement w is chosen from a uniform distribution from −W to W. A linear warping function W(t) is defined so that the start point w0 is mapped to the point w0+w and that the boundary points t=0 and t=τ-1 are fixed:

- Warping is defined so that the warped features xwarp(t) (here, log-mel frequency coefficients) at time t are related to the original features xorig(t) by:

- (2) Frequency masking with parameter F: A mask size f is chosen from a uniform distribution from 0 to F. The consecutive log-mel frequency channels [f0, f0+f) are masked.
- (3) Time masking with parameter T: A mask size t is chosen from a uniform distribution from 0 to T. The consecutive time steps [t0, t0+t) are masked, where t0 is chosen from [0, τ-t).
1.2. Adaptive Time Masking
- The original SpecAugment policies consist of applying these three augmentations a fixed number of times.
- In large scale datasets that contain disparate domains of inputs, there is a large variance in the length of the input audio.
- Thus, a fixed number of time masks may not be adequate for such tasks, as the time masking may be too weak for longer utterances, or too severe for shorter ones.
- 2 different ways time masking are introduced.
- Adaptive multiplicity: The number, or multiplicity, of time masks Mt-mask is set to be M_t-mask = ⌊pM·τ⌋ for the multiplicity ratio pM.
- Adaptive size: The time mask parameter is set to be T=⌊pS·τ⌋ for the size ratio pS.
- In this paper, the number of time masks is capped at 20 when using adaptive time masking, so that Mt-mask is given by:

2. Results
2.1. LibriSpeech 960h

- Listen, Attend and Spell (LAS)-6–1280 (L) is used.
- A shallow fusion with LSTM language model, i.e. a 3-layer LSTM with width 4096, is used with a resulting word-level perplexity of 63.6 on the dev-set transcripts.
The adaptive policy performs better than the fixed policy, and observe gain in performance both before and after shallow fusion with the language model
2.2. Google Multidomain Dataset
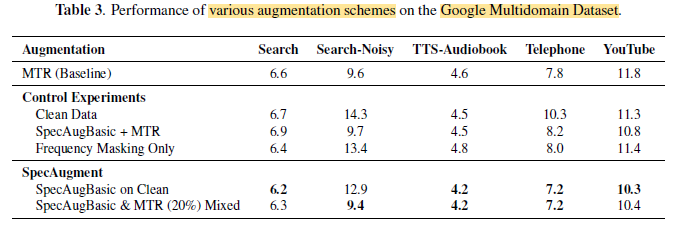
- 5 test sets — Search, Search-Noisy, TTS-Audiobook, Telephony and YouTube, are used for evaluation.
- The input data is augmented by using a room simulator [3].
- The test set Search-Noisy is constructed by applying the perturbations to the Search test set.
- The network input is a log-mel frequency spectrogram obtained from the audio using 32 msec frame windows with 10 msec shift. The log-mel frequency coefficients have 128 dimensions, and are stacked with height 512 with stride 3.
- Multistyle TRaining (MTR) [3]: a mixed room simulator is used to combine clean audio with a large library of noise audio, is employed to augment the input data.
- SpecAugBasic: A vanilla SpecAugment policy that has 2 frequency masks and 2 time masks with T = 50. Time warping has not been used. As a control experiment, the network is also trained on data augmented only using frequency masking with two masks of F = 27.
- An RNN-T model described in [28] is trained. The encoder is an 8-layer uni-directional LSTM with cell size 2048, while the decoder is a 2-layer LSTM with the same cell size. No language model is used.
- When SpecAugment is applied on top of MTR, the performance degrades below the baseline across all test sets.
When SpecAugBasic is applied to the clean utterances, it outperforms the baseline across all “natural test sets,” while it performs worse on the synthetic test set obtained by applying MTR to Search-domain utterances.
This degradation, however, can be addressed by ensembling SpecAugmented data with MTR data, as shown in the last row of the table.
