Brief Review — Conformer: Convolution-augmented Transformer for Speech Recognition
Adds Convolution into Transformer
Conformer: Convolution-augmented Transformer for Speech Recognition
Conformer, by Google Inc.
2020 InterSpeech, Over 2600 Citations (Sik-Ho Tsang @ Medium)Acoustic Model / Automatic Speech Recognition (ASR) / Speech-to-Text Modeling
1991 … 2019 [SpecAugment] [Cnv Cxt Tsf] 2020 [FAIRSEQ S2T] [PANNs]
==== My Other Paper Readings Are Also Over Here ====
- Transformer models are good at capturing content-based global interactions, while CNNs exploit local features effectively.
- In this paper, a convolution-augmented Transformer for speech recognition, namely Conformer, is proposed.
Outline
- Conformer
- Results
1. Conformer
1.1. Overall Architecture

- The proposed audio encoder first processes the input with a convolution subsampling layer and then with a number of conformer blocks.
A conformer block is composed of four modules stacked together, i.e, a feed-forward module, a self-attention module, a convolution module, and a second feed-forward module in the end.
1.2. Multi-Headed Self-Attention Module

- Relative sinusoidal positional encoding, used in Transformer-XL, is integrated in the multi-headed self-attention (MHSA), to generalize better on different input length.
- Pre-norm residual units with Dropout is used, which helps training and regularizing deeper models.
1.3. Convolution Module

- The convolution module starts with a gating mechanism — a pointwise convolution and a gated linear unit (GLU). This is followed by a single 1-D depthwise convolution layer.
- Batchnorm is deployed just after the convolution to aid training deep models.
1.4. Feed Forward Module

- The feed forward module is composed of two linear transformations and a nonlinear activation in between.
- A residual connection is added over the feed-forward layers, followed by layer normalization. This structure is also adopted by Transformer ASR models [7, 24].
1.5. Conformer Block
- The Conformer block contains two Feed Forward modules sandwiching the Multi-Headed Self-Attention module and the Convolution module, as in Figure 1.
- This sandwich structure is inspired by Macaron-Net [18], which proposes replacing the original feed-forward layer in the Transformer block into two half-step feed-forward layers, one before the attention layer and one after.
- As in Macron-Net, half-step residual weights are employed in the feed-forward (FFN) modules. The second feed-forward module is followed by a final layernorm layer:
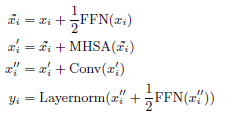
- The ablation study shows that two Macaron-net style feed-forward layers with half-step residual connections sandwiching the attention and convolution modules in between provides a significant improvement over having a single feedforward module in the Conformer architecture.
1.6. Model Variants
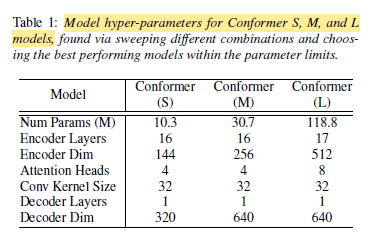
- Conformer S, M, & L sizes are constructed as above.
2. Results

- LibriSpeech is used as the dataset for performance evaluation.
- For the proposed conformer, 3-layer LSTM language model (LM) is used, with width 4096 trained on the LibriSpeech langauge model corpus with the LibriSpeech 960h transcripts added, tokenized with the 1k WPM built from LibriSpeech 960h.
- This LM is a common practice to further boost the performance.
Without a language model, the performance of the medium model already achieve competitive results of 2.3/5.0 on test/testother outperforming the best known Transformer, LSTM based model, or a similar sized convolution model.
With the language model added, the proposed model achieves the lowest word error rate among all the existing models.
- (There are numerous ablation experiments in the paper, please read it directly if interested.)
