Brief Review — Text Embeddings by Weakly-Supervised Contrastive Pre-training
E5, EmbEddings from bidirEctional Encoder rEpresentations
Text Embeddings by Weakly-Supervised Contrastive Pre-training
E5, by Microsoft Corporation
2022 arXiv v2, Over 330 Citations (Sik-Ho Tsang @ Medium)Sentence Embedding / Dense Text Retrieval
2017 [InferSent] 2018 [Universal Sentence Encoder (USE)] 2019 [Sentence-BERT (SBERT)] 2020 [Multilingual Sentence-BERT] [Retrieval-Augmented Generation (RAG)] [Dense Passage Retriever (DPR)] [IS-BERT] 2021 [Fusion-in-Decoder] [Augmented SBERT (AugSBERT)] [SimCSE] [ANCE] 2024 [Multilingual E5]
==== My Other Paper Readings Are Also Over Here ====
- E5, EmbEddings from bidirEctional Encoder rEpresentations, is proposed, which is trained in a contrastive manner with weak supervision signals from the proposed curated large-scale text pair dataset (called CCPairs).
- Later, Multilingual E5 is proposed.
Outline
- CCPairs: A Large Collection of Text Pair Dataset
- E5
- Results
1. CCPairs: A Large Collection of Text Pair Dataset

1.1. Harvesting Semi-Structured Data Sources
- A text pair dataset CCPairs (Colossal Clean text Pairs) is curated.
- Let (q, p) denote a text pair consisting of a query q and a passage p.
- The dataset includes (post, comment) pairs from Reddit, (question, upvoted answer) pairs from Stackexchange, (entity name + section title, passage) pairs from English Wikipedia, (title, abstract) and citation pairs from Scientific papers [36], and (title, passage) pairs from Common Crawl web pages and various News sources.
- Simple heuristic rules are applied to filter data from Reddit and Common Crawl, e.g.: Reddit comments that are either too long (> 4096 characters) or receive score less than 1, remove passages from web pages with high perplexity.
- Finally, there are ∼ 1.3 billion text pairs.
1.2. Consistency-based filter
- To further improve data quality and make training costs manageable, the model is first trained on the 1.3B noisy text pairs, and then used to rank each pair against a pool of 1 million random passages. A text pair is kept only if it falls in the top-k ranked lists.
- The model’s prediction should be consistent with the training labels.
- Here k = 2 based on manual inspection of data quality.
- After this step, there are ∼ 270M text pairs for contrastive pre-training.
2. E5
2.1. Contrastive Pre-training with Unlabeled Data
- The embeddings can be trained with only unlabeled text pairs from CCPairs with contrastive pretraining.
- A second-stage fine-tuning on small, high-quality labeled datasets can be performed to further boost the quality of the resulted embeddings.
- Given a collection of text pairs {(qi, pi)}, a list of negative passages non-{(qi, pi)} for the i-th example., the InfoNCE contrastive loss from SimCLR is used:

- where sθ(q, p) is a scoring function between query q and passage p parameterized by θ.
- Following the popular biencoder architecture, a pre-trained Transformer encoder is used. Average pooling is used over the output layer to get fixed-size text embeddings Eq and Ep. The score is the cosine similarity scaled by a temperature hyperparameter τ = 0.01:

- A shared encoder is used for all input texts and the symmetry is broken by adding two prefix identifiers “query:” and “passage:” to q and p respectively.
- In-batch negatives, is used, whhich is found to be stable, and outperforms methods such as MoCo.
2.2. Fine-tuning with Labeled Data
- Further training on labeled data can inject human knowledge into the model to boost the performance.
- Authors choose to further train with a combination of 3 datasets: NLI (Natural Language Inference), MS-MARCO passage ranking dataset [8], and NQ (Natural Questions) dataset [30, 32].
- Empirically, tasks like STS (Semantic Textual Similarity) and linear probing benefit from NLI data, while MS-MARCO and NQ datasets transfer well to retrieval tasks.
- Hard negatives are mined and knowledge distillation from a cross-encoder (CE) teacher model is used for the MS-MARCO and NQ datasets.
- For the NLI dataset, contradiction sentences are regarded as hard negatives.
- The loss function is a linear interpolation between contrastive loss Lcont for hard labels and KL divergence DKL for distilling soft labels from the teacher model.
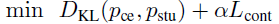
- Where pce and pstu are the probabilities from the cross-encoder teacher model and our student model. α is a hyperparameter to balance the two loss functions.
3. Results
3.1. BEIR

- When averaged over all 15 datasets, E5-PTbase outperforms the classic BM25 algorithm by 1.2 points.
- To the best of authors’ knowledge at that moment, this is the first reported result that an unsupervised model can beat BM25 on the BEIR benchmark.
- When scaling up to E5-PTlarge, further benefits are shown from 42.9 to 44.2.
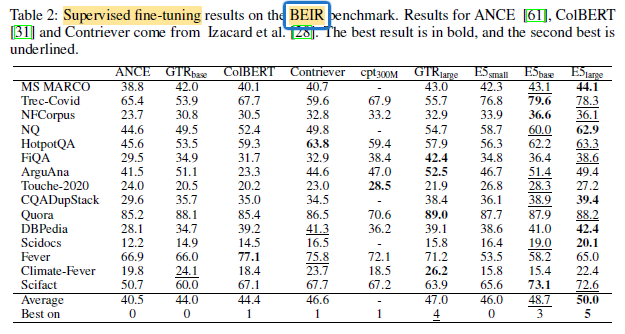
- E5base model achieves an average nDCG@10 of 48.7, already surpassing existing methods with more parameters such as GTRlarge [43].
3.2. MTEB
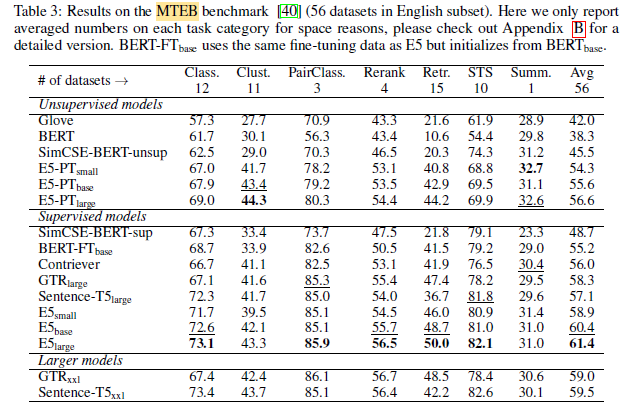
E5 models not only substantially outperform existing ones with similar sizes, but also match the results of much larger models.
3.3. Zero-Shot Text Classification

By formulating text classification as embedding matching between input and label texts, the proposed model can be much better than the “majority” baseline in a zero-shot setting.
3.4. Ablation Study
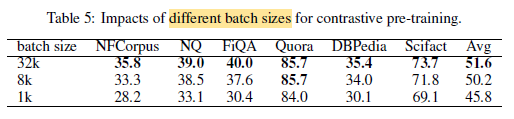
- Increasing batch size from 1K to 32K leads to consistent gains across all 6 datasets.
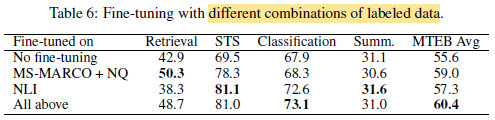
Combining all of the datasets leads to the best overall scores on the MTEB benchmark.
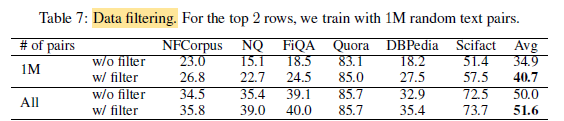
Deep learning models should be quite robust to dataset noises, data filtering still has benefits in improving training efficiency and model quality.
