Review — SimCLR: A Simple Framework for Contrastive Learning of Visual Representations

A Simple Framework for Contrastive Learning of Visual Representations
SimCLR, by Google Research, Brain Team
2020 ICML, Over 3600 Citations (Sik-Ho Tsang @ Medium)
Self-Supervised Learning, Unsupervised Learning, Contrastive Learning, Representation Learning, Image Classification, Object Detection
- SimCLR, a Simple framework for Contrastive Learning of visual Representations, is proposed.
- A recently proposed contrastive self-supervised learning algorithms is simplified, without requiring specialized architectures or a memory bank.
- Few major components are systematically studied:
- Composition of data augmentations plays a crucial role.
- A learnable nonlinear transformation between the representation and the contrastive loss substantially improves the representation quality.
- Contrastive learning benefits from larger batch sizes and more training steps.
- This is a paper from Prof. Hinton’s Group.
Outline
- SimCLR Framework
- SOTA Comparison
1. SimCLR Framework

- SimCLR learns representations by maximizing agreement between differently augmented views of the same data example via a contrastive loss in the latent space, as shown above.
1.1. Data Augmentation
- A stochastic data augmentation module that transforms any given data example randomly resulting in two correlated views of the same example, denoted ~xi and ~xj, as positive pairs.
- Three simple augmentations are applied sequentially: random cropping followed by resize back to the original size, random color distortions, and random Gaussian blur.

- By randomly cropping images, the contrastive prediction tasks are sampled that include global to local view (B→A) or adjacent view (D→C) prediction.

- The above data augmentation operators are studied.
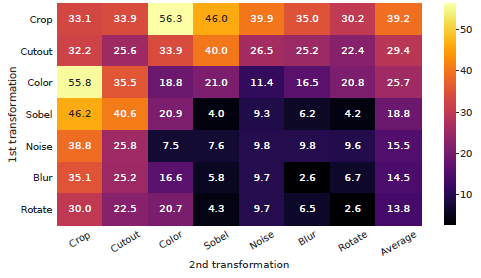
- No single transformation suffices to learn good representations.
The combination of random crop and color distortion is crucial to achieve a good performance.
1.2. Base Encoder
- A neural network base encoder f() that extracts representation vectors from augmented data examples.
ResNet is used to obtain hi=f(~xi)=ResNet(~xi) where hi is d-dimensional, which is the output after the average pooling layer.
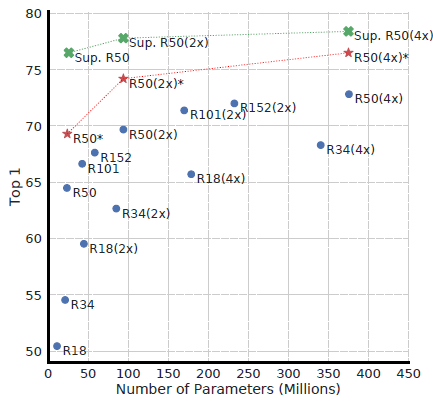
Unsupervised learning benefits more from bigger models than its supervised counterpart.
1.3. Projection Head
- A small neural network projection head g() that maps representations to the space where contrastive loss is applied.
- A MLP with one hidden layer is used to obtain zi:
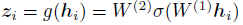
- where σ is a ReLU nonlinearity.
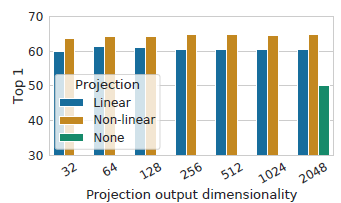
It is found that it is beneficial to define the contrastive loss on zi’s rather than hi’s.
1.4. Contrastive Loss
- A minibatch of N examples is randomly sampled.
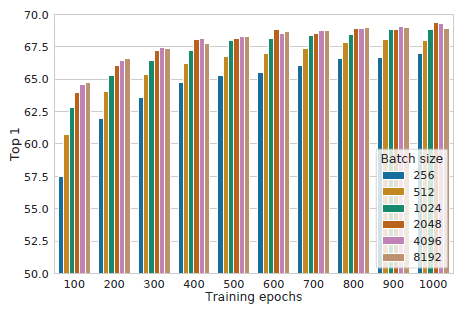
Large batch size is beneficial, longer training time is also beneficial.
- The contrastive prediction task is defined on pairs of augmented examples derived from the minibatch, resulting in 2N data points.
- Given a positive pair, the other 2(N-1) augmented examples within a minibatch as negative examples.
- The loss function for a positive pair of examples (i, j) is defined as:
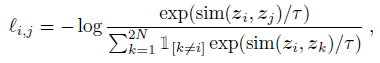
- where sim(,) is cosine similarity, τ is the temperature parameter.
- The final loss is computed across all positive pairs, both (i, j) and (j, i), in a mini-batch.
- (For NCE, please feel free to read NCE, Negative Sampling, CPC.)
- (For temperature parameter, please feel free to read Distillation.)
It is named as NT-Xent (the normalized temperature-scaled cross entropy loss).


Different loss functions are tried, NT-Xent is the best one.
2. SOTA Comparison
2.1. Linear Evaluation on ImageNet


The best result obtained with ResNet-50 (4×) using SimCLR can match the supervised pretrained ResNet-50.
2.2. Few Labels Evaluation on ImageNet

Again, SimCLR significantly improves over state-of-the-art with both 1% and 10% of the labels.
2.3. Transfer Learning
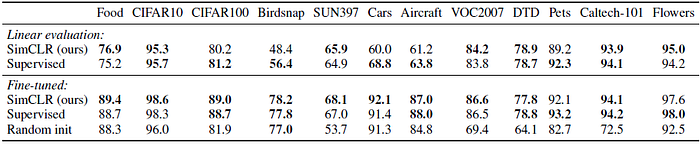
- The ResNet-50 (4×) model is used.
When fine-tuned, SimCLR significantly outperforms the supervised baseline on 5 datasets, whereas the supervised baseline is superior on only 2 (i.e. Pets and Flowers).
- On the remaining 5 datasets, the models are statistically tied.
There are appendices providing many details and other results, please feel free to read the paper directly if interested.
Later on, MoCo extends as MoCo v2 based on SimCLR’s findings.
Reference
[2020 ICML] [SimCLR]
A Simple Framework for Contrastive Learning of Visual Representations
Unsupervised/Self-Supervised Learning
1993 [de Sa NIPS’93] 2008–2010 [Stacked Denoising Autoencoders] 2014 [Exemplar-CNN] 2015 [Context Prediction] [Wang ICCV’15] 2016 [Context Encoders] [Colorization] [Jigsaw Puzzles] 2017 [L³-Net] [Split-Brain Auto] [Motion Masks] [Doersch ICCV’17] 2018 [RotNet/Image Rotations] [DeepCluster] [CPC/CPCv1] [Instance Discrimination] 2020 [CMC] [MoCo] [CPCv2] [PIRL] [SimCLR]
