Brief Review — YOLACT: Real-time Instance Segmentation
YOLACT, You Only Look At CoefficienTs, One-Stage Instance Segmentation

YOLACT: Real-time Instance Segmentation,
YOLACT, by University of California, Davis,
2019 ICCV, Over 1000 Citations (Sik-Ho Tsang @ Medium)
Instance Segmentation, Semantic Segmentation
- You Only Look At CoefficienTs (YOLACT) is proposed, which is a simple, fully-convolutional model for real-time instance segmentation, which is trained using one GPU only.
- It has two parallel subtasks: (1) generating a set of prototype masks and (2) predicting per-instance mask coefficients. Then, instance masks are produced by linearly combining the prototypes with the mask coefficients.
- FastNMS is also proposed, which has a drop-in 12 ms faster replacement for standard NMS, with only a marginal performance penalty.
Outline
- You Only Look At CoefficienTs (YOLACT)
- Results
1. You Only Look At CoefficienTs (YOLACT)

1.1. Motivations
The goal is to add a mask branch to an existing one-stage object detection model.
- To do this, the complex task of instance segmentation is broken down into two simpler, parallel tasks that can be assembled to form the final masks.
- The first branch uses an FCN to produce a set of image-sized “prototype masks” that do not depend on any one instance.
- The second adds an extra head to the object detection branch to predict a vector of “mask coefficients” for each anchor that encode an instance’s representation in the prototype space.
- Finally, for each instance that survives NMS, a mask is constructed for that instance by linearly combining the work of these two branches.
1.2. Prototype Generation

- The prototype generation branch (protonet) predicts a set of k prototype masks for the entire image. An FCN is attached to a backbone feature layer whose last layer has k channels (one for each prototype).
- P3 in FPN is used because its largest feature layers are the deepest. It is upsampled to one fourth the dimensions of the input image to increase performance on small objects.
- The labels shown in the figure above denote feature size and channels for an image size of 550×550. Arrows indicate 3×3 conv layers, except for the final conv which is 1×1. The increase in size is an upsample followed by a conv.

- E.g.: prototypes 1–3: By combining these partition maps, the network can distinguish between different (even overlapping) instances of the same semantic class;
- E.g., in image d, the green umbrella can be separated from the red one by subtracting prototype 3 from prototype 2.
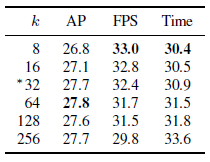
- 32 is chosen for its mix of performance and speed.
1.3. Mask Coefficients
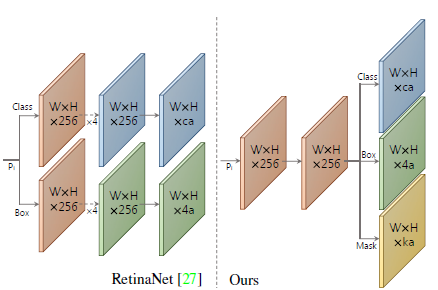
- For mask coefficient prediction, a third branch is simply added in parallel that predicts k mask coefficients, one corresponding to each prototype. Thus, instead of producing 4+c coefficients per anchor, 4+c+k coefficients are produced.
- tanh is applied to the k mask coefficients, which produces more stable outputs over no nonlinearity.
1.4. Mask Assembly
- The work of the prototype branch and mask coefficient branch are combined using a linear combination. These operations can be implemented efficiently using a single matrix multiplication and sigmoid:
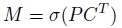
- where P is an h×w×k matrix of prototype masks and C is a n×k matrix of mask coefficients for n instances surviving NMS and score thresholding.
1.5. Loss Functions
- 3 Losses are used: Classification loss Lcls, box regression loss Lbox and mask loss Lmask with the weights 1, 1.5, and 6.125 respectively.
- Lcls and Lbox are similar to those in SSD.
- Lmask is the pixel-wise binary cross entropy between assembled masks M and the ground truth masks Mgt:

- The final masks are cropped with the predicted bounding box during evaluation. During training, final masks are cropped with the ground truth bounding box, Lmask is divided by the ground truth bounding box area to preserve small objects in the prototypes.
1.6. Backbone Detector
- ResNet-101 with FPN and a base image size of 550×550 are used.
- FPN is modified by not producing P2 and producing P6 and P7 as successive 3 × 3 stride 2 conv layers starting from P5 (not C5) and place 3 anchors with aspect ratios [1, 1/2, 2] on each. Scales of P3 to P7 are [24, 48, 96, 192, 384].
- For the prediction head attached to each Pi, one 3×3 conv is shared by all three branches, and then each branch gets its own 3 × 3 conv in parallel.
1.7. FastNMS
- Traditional NMS is useful to suppress duplicate detections but it is performed sequentially, which is slow.
- To perform FastNMS, a c×n×n pairwise IoU matrix X is computed for the top n detections sorted descending by score for each of c classes.
- Then, detections are removed if there are any higher-scoring detections with a corresponding IoU greater than some threshold t.
- AP is dropped a bit since there are slightly more detections removed.
1.8. Semantic Segmentation Loss
- An extra loss is added to the model during training using modules not executed at test time. This effectively increases feature richness while at no speed penalty.
- A 1×1 conv layer with c output channels is simply added directly to the largest feature map (P3) in the backbone. Since each pixel can be assigned to more than one class, sigmoid and c channels are used instead of softmax and c+1. This loss is given a weight of 1 and results in a +0.4 mAP boost.
2. Results
2.1. Quantitative Results

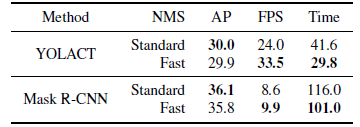
YOLACT-550 offers competitive instance segmentation performance while at 3.8× the speed of the previous fastest instance segmentation method on COCO.
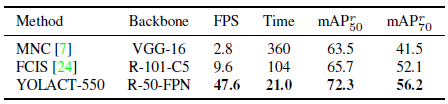
YOLACT clearly outperforms popular approaches that report SBD performance, while also being significantly faster.
2.2. Qualitative Results

Masks generated by YOLACT for large objects are noticeably higher quality than those of Mask R-CNN and FCIS.
- For instance, YOLACT produces a mask that cleanly follows the boundary of the arm, whereas both FCIS and Mask R-CNN have more noise.

- This base model achieves 29.8 mAP at 33.0 fps. All images have the confidence threshold set to 0.3.
Later, YOLACT++ is published in 2022 TPAMI.
Reference
[2019 ICCV] [YOLACT]
YOLACT: Real-time Instance Segmentation
1.6. Instance Segmentation
2014–2019 … [YOLACT] 2020 [Open Images] 2021 [PVT, PVTv1] [Copy-Paste] 2022 [PVTv2]
