Review — PVTv2: Improved Baselines with Pyramid Vision Transformer
Outperforms PVT/PVTv1, Swin Transformer, Twins
PVTv2: Improved Baselines with Pyramid Vision Transformer
PVTv2, by Nanjing University, The University of Hong Kong, Nanjing University of Science and Technology, IIAI, and SenseTime Research
2022 CVMJ, Over 90 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Vision Transformer, ViT, PVT/PVTv1, Swin Transformer
1. Limitations in PVT/PVTv1
- There are three main limitations in PVTv1 as follows:
- Similar to ViT, when processing high-resolution input (e.g., shorter side being 800 pixels), the computational complexity of PVTv1 is relatively large.
- PVTv1 treats an image as a sequence of non-overlapping patches, which loses the local continuity of the image to a certain extent.
- The position encoding in PVTv1 is fixed-size, which is inflexible for process images of arbitrary size.
2. PVTv2
2.1. Linear Spatial Reduction Attention (Linear SRA)

- Different from Spatial Reduction Attention (SRA) in PVTv1 which uses convolutions for spatial reduction, linear SRA uses average pooling to reduce the spatial dimension (i.e., h×w) to a fixed size (i.e., P×P) before the attention operation.
- So, linear SRA enjoys linear computational and memory costs like a convolutional layer. Specifically, given an input of size h×w×c, the complexity of SRA and linear SRA are:

- where R is the spatial reduction ratio of SRA in PVTv1. P is the pooling size of linear SRA, which is set to 7.
2.2. Overlapping Patch Embedding (OPE)

- To model the local continuity information, PVTv2 utilizes overlapping patch embedding to tokenize images.
- Specifically, the patch window is enlarged, making adjacent windows overlap by half of the area, and the feature map is padded with zeros to keep the resolution.
- In this work, convolution with zero paddings is used to implement overlapping patch embedding.
2.3. Convolutional Feed-Forward Network

- Inspired by some previous work, such as CPVT, the fixed-size position encoding is removed, and zero padding position encoding is introduced into PVTv1.
- A 3×3 depth-wise convolution (DWConv), in MobileNetV1, with the padding size of 1 is added between the first fully-connected (FC) layer and GELU in feed-forward networks.
2.4. PVTv2 Variants
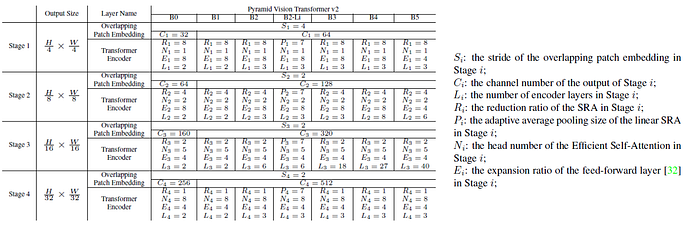
- PVTv2 Variants, B0, B1, B2, B2-Li, B3, B4 and B5, are designed.
- “-Li” denotes PVTv2 with linear SRA.
- The design follows the principles of ResNet. (1) the channel dimension increase while the spatial resolution shrink with the layer goes deeper. (2) Stage 3 is assigned to most of the computation cost.
3. Experimental Results
3.1. ImageNet

PVTv2 is the state-of-the-art method on ImageNet-1K classification. Compared to PVT, PVTv2 has similar flops and parameters, but the image classification accuracy is greatly improved.
- PVTv2-B5 achieves 83.8% ImageNet top-1 accuracy, which is 0.5% higher than Swin Transformer and Twins, while parameters and FLOPS are fewer.
Compared to other recent counterparts, PVTv2 series also has large advantages in terms of accuracy and model size.
3.2. COCO
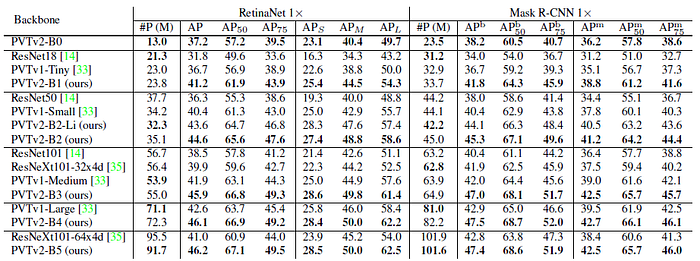
- PVTv2-B4 archive 46.1 AP on top of RetinaNet, and 47.5 APb on top of Mask R-CNN, surpassing the models with PVTv1 by 3.5 AP and 4.6 APb, respectively.
PVTv2 significantly outperforms PVTv1 on both one-stage and two-stage object detectors with similar model size.

- For a fair comparison between PVTv2 and Swin Transformer, all settings are kept the same for training.
PVTv2 obtain much better AP than Swin Transformer among all the detectors, showing its better feature representation ability.
- For example, on ATSS, PVTv2 has similar parameters and flops compared to Swin-T, but PVTv2 achieves 49.9 AP, which is 2.7 higher than Swin-T.
PVTv2-Li can largely reduce the computation from 258 to 194 GFLOPs, while only sacrificing a little performance.
3.3. ADE20K
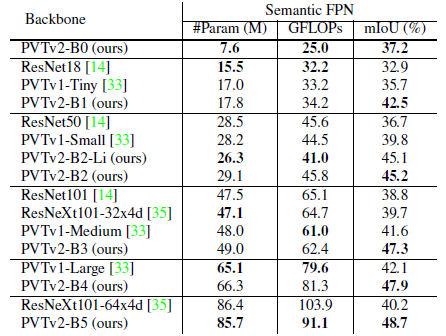
- Semantic FPN framework is used.
- With almost the same number of parameters and GFLOPs, PVTv2-B1/B2/B3/B4 are at least 5.3% higher than PVTv1-Tiny/Small/Medium/Large.
PVTv2 consistently outperforms PVTv1 and other counterparts.
3.4. Ablation Study
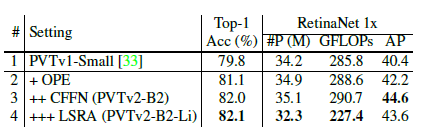
- Overlapping patch embedding (OPE) is important. Comparing #1 and #2, the model with OPE obtains better top-1 accuracy (81.1% vs. 79.8%) on ImageNet and better AP (42.2% vs. 40.4%) on COCO than the one with original patch embedding (PE).
- Convolutional feed-forward network (CFFN) matters. As reported in #2 and #3, CFFN brings 0.9 points improvement on ImageNet (82.0% vs. 81.1%) and 2.4 points improvement on COCO, which demonstrates its effectiveness.
- Linear SRA (LSRA) contributes to a better model. LSRA significantly reduces the computation overhead (GFLOPs) of the model by 22%, while keeping a comparable top-1 accuracy on ImageNet (82.1% vs. 82.0%).
3.5. Computational Complexity
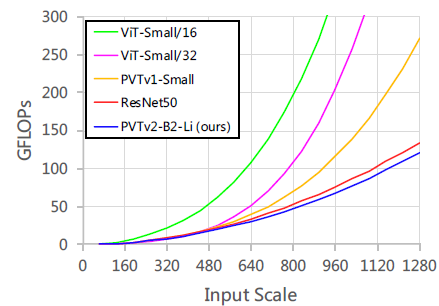
PVTv2-Li successfully addresses the high computational overhead problem caused by the attention layer.
3.6. Qualitative Results

Reference
[2022 CVMJ] [PVTv2]
PVTv2: Improved Baselines with Pyramid Vision Transformer
Image Classification
1989 … 2021 [Learned Resizer] [Vision Transformer, ViT] [ResNet Strikes Back] [DeiT] [EfficientNetV2] [MLP-Mixer] [T2T-ViT] [Swin Transformer] [CaiT] [ResMLP] [ResNet-RS] [NFNet] [PVT, PVTv1] [CvT] [HaloNet] [TNT] [CoAtNet] [Focal Transformer] [TResNet] [CPVT] [Twins] 2022 [ConvNeXt] [PVTv2]
