Brief Review —Audio-based snore detection using deep neural networks
CQT + CNN + LSTM
Audio-based snore detection using deep neural networks
CQT + CNN + LSTM, by Eindhoven University of Technology, Philips Research, and Sleep Medicine Center Kempenhaeghe
2021 Elsevier J. CMPB, Over 30 Citations (Sik-Ho Tsang @ Medium)Snore Sound Classification
2017 [INTERSPEECH 2017 Challenges: Addressee, Cold & Snoring] 2018 [MPSSC] [AlexNet & VGG-19 for Snore Sound Classification] 2019 [CNN for Snore] 2020 [Snore-GAN]
==== My Healthcare and Medical Related Paper Readings ====
==== My Other Paper Readings Are Also Over Here ====
- 38 subjects were recorded for snore sound by a total of 5 microphones placed at strategic positions around the bed.
- The sound signal is converted into CQT then fed into a model composing of CNN+LSTM for classifying snore/non-snore sounds.
- There is a paper using CQT + HPSS + CNN + LSTM in 2024 Applied Acoustics.
Outline
- Dataset Construction
- CQT + CNN + LSTM
- Results
1. Dataset Construction
1.1. Data Collection

The dataset used is a subset of the large SOMNIA database [32]. Based on availability of audio recordings, 38 subjects were included.
1.2. Data Annotation
- An automatic selection of sound intervals described by Arsenali et al. [14] is used. This procedure resulted in an average of 4756 sound events per subject (min and max of 1793 and 8509, respectively).
- Then, a manual annotation is performed to classify the sound in terms of snore, non-snore, probably snore and probably non- snore events, done by an experienced sleep technician.
This process resulted in a total of 20225 annotated sound events, including 7936 (39.2%) snore events (ranged from 25 to 439 per subject), 10476 (51.8%) non-snore events, and 1813 (9%) unsure events (annotated as probably snore and probably non-snore), which are discarded.
2.2. CQT + CNN + LSTM

2.1. Preprocessing
- A low pass filter with a cutoff-frequency of 50 Hz and an order of 3 was applied to its associated audio signal to remove the electrical power supply noise.
2.2. CQT
- After cutting the events to 3.5s, the signal went through CQT [18, 19], resulting its 2D spectrogram representation, where CQT is:
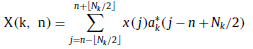
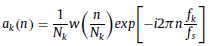
The CQT spectrogram has a higher frequency resolution in the low frequency range and a higher time resolution in the high frequency range.
- The frequency scale of CQT is close to the human auditory system [20], which is similar to the well-known Mel-frequency scale, however, with even more details in the low frequency bands.
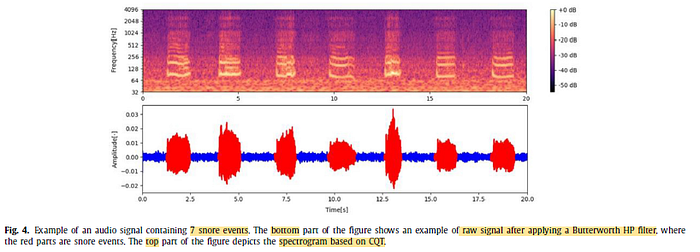
As seen above, the dominant frequency components of snore events are mainly distributed over the low frequency range and CQT spectrograms provide an accurate representation.
2.3. CNN + LSTM
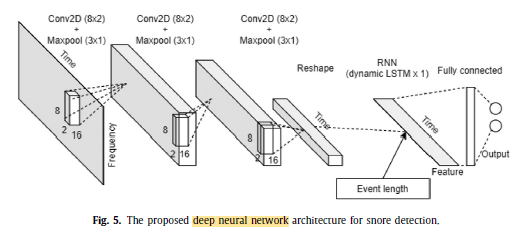
3 Convolutional layers with Max pooling and ReLU are used.
Then, a LSTM layer with 64 hidden units is used.
A fully connected layer with softmax is at the end for classification.
3. Results

The non-snore events are better identified than snore events, with an average difference of 5.5%, a maximum of 6.9 % for M2 and a min- imum of 4.2% for M4.
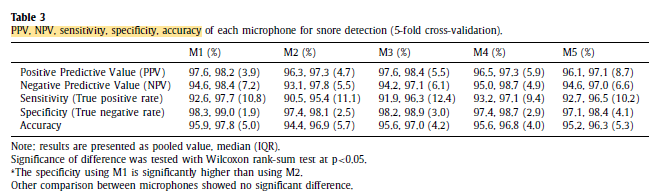
M1-M5 show a similar trend as the overall performance with M1 having a better performance, and M2 and M5 having a worse performance.
Yet, the microphone placement does not have a major effect on the detection performance. Still, it is recommended hanging the microphone closely above the sleeper’s head, as M1 has the best overall performance.
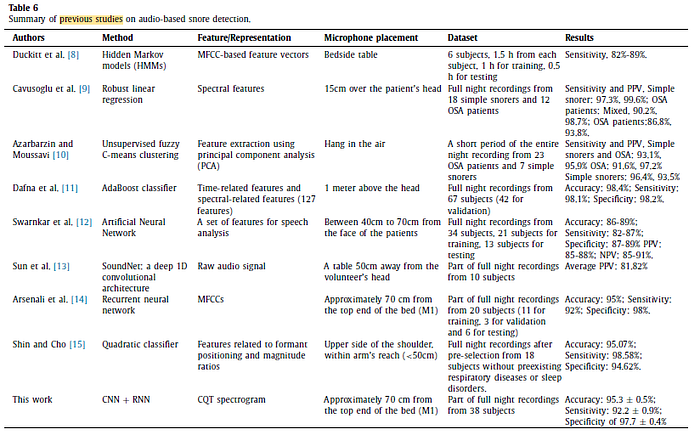
- Most methods require multiple features to be extracted from audio sig- nals, which requires specific knowledge in feature extraction and selection algorithms. By contrast, the proposed deep NN approach algorithm can obtain features automatically using CNN layers, which is the main novelty of this study.
