[Paper] CAM: Learning Deep Features for Discriminative Localization (Weakly Supervised Object Localization)
Revisit Global Average Pooling (GAP), Weakly Supervised Object Localization While Image Classification, Outperforms Backprop

In this story, Learning Deep Features for Discriminative Localization (CAM), by MIT, is presented. In this story:
- Global Average Pooling (GAP) is used at the near end of the network.
- By using GAP, Class Activation Mapping (CAM) technique is proposed for Weakly Supervised Object Localization (WSOL)
- Object localization and image classification are performed in a single forward-pass.
As described in one 2020 CVPR WSOL paper, it’s surprising that it’s still one of the state-of-the-art WSOL approaches with superior performance. This is a paper in 2016 CVPR with over 3000 citations. (Sik-Ho Tsang @ Medium)
1. Class Activation Mapping (CAM) Using Global Average Pooling (GAP)
1.1. Network Using GAP for CAM

- As illustrated in the above figure, global average pooling (GAP) outputs the spatial average of the feature map of each unit at the last convolutional layer. A weighted sum of these values is used to generate the final output.
- Similarly, we can compute a weighted sum of the feature maps of the last convolutional layer to obtain our class activation maps.
- For a given class c, the input to the softmax is Sc:

- where fk(x, y) is represent the activation of unit k in the last convolutional layer at spatial location (x, y), and wck is the weight corresponding to class c for unit k. Essentially, wck indicates the importance of Fk for class c.
- Mc is defined as the class activation map for class c, where each spatial element is given by:

- where Mc(x, y) directly indicates the importance of the activation at spatial grid (x, y) leading to the classification of an image to class c.
The class activation map (CAM) is simply a weighted linear sum of the presence of these visual patterns at different spatial locations.

- The above figure shows some examples of CAM
- The maps highlight the discriminative image regions used for image classification, the head of the animal for briard and the plates in barbell.
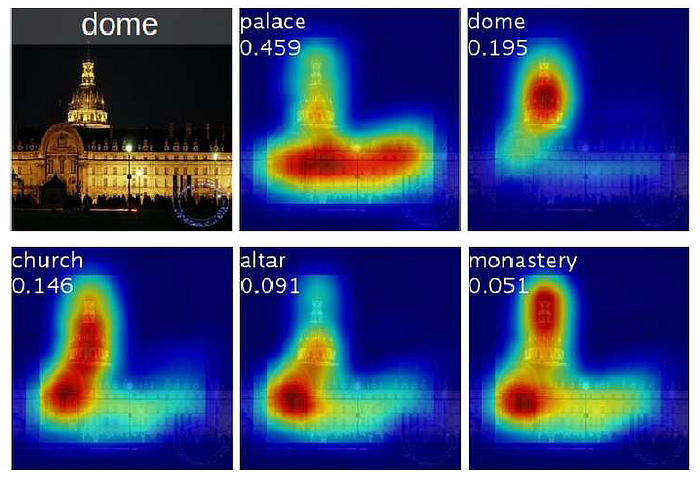
- In the above figure, the differences are highlighted in the CAMs for a single image when using different classes c to generate the maps.
- It is observed that the discriminative regions for different categories are different even for a given image.
1.2. Weakly Supervised Object Localization (WSOL)
- To generate a bounding box from the CAMs, a simple thresholding technique is used to segment the heatmap.
First, segment the regions of which the value is above 20% of the max value of the CAM.
Then, take the bounding box that covers the largest connected component in the segmentation map.

- The above figure shows some example of GoogLeNet using GAP for WSOL.
1.3. GAP vs GMP
- GAP: It is believed that GAP loss encourages the network to identify the extent of the object as compared to GMP which encourages it to identify just one discriminative part.
- The value can be maximized by finding all discriminative parts of an object as all low activations reduce the output of the particular map.
- GMP: On the other hand, for Global Max Pooling (GMP), low scores for all image regions except the most discriminative one do not impact the score.
- In experiment, GMP achieves similar classification performance as GAP, GAP outperforms GMP for localization.
2. AlexNet, VGGNet, GoogLeNet Using GAP for CAM
- AlexNet, VGGNet, and GoogLeNet are modified to have GAP for CAM.
- The fully-connected layers before the final output are removed, and GAP is used to replaced them followed by a fully connected softmax.
- For AlexNet, the layers after conv5 (i.e., pool5 to prob) are removed resulting in a mapping resolution of 13×13.
- For VGGNet, the layers after conv5–3 (i.e., pool5 to prob) are removed, resulting in a mapping resolution of 14×14.
- For GoogLeNet, the layers after inception4e (i.e., pool4 to prob) are removed, resulting in a mapping resolution of 14×14.
- To each of the above networks, a convolutional layer of size 3×3, stride 1, pad 1 with 1024 units is added, followed by a GAP layer and a softmax layer.
- Each network is fine-tuned by ImageNet.
3. Experimental Results
3.1. Classification

- In most cases there is a small performance drop of 1 − 2% when removing the additional layers from the various networks.
- Two convolutional layers are added just before GAP resulting in the AlexNet*-GAP network, so that AlexNet*-GAP performs comparably to AlexNet.
- It is noted that GoogLeNet-GAP and GoogLeNet-GMP have similar performance on classification, as expected.
3.2. Weakly-Supervised Object Localization (WSOL)
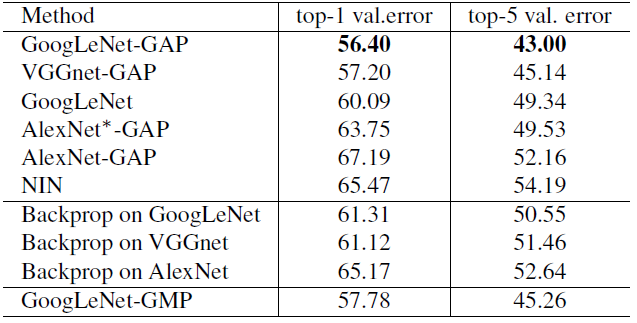
- GAP networks outperform all the baseline approaches with GoogLeNet-GAP achieving the lowest localization error of 43% on top-5.
- The result is remarkable as there is no annotated bounding box during training.
- And the CAM approach significantly outperforms the Backprop approach.
- GoogLeNet-GAP outperforms GoogLeNet-GMP by a reasonable margin illustrating the importance of average pooling over max pooling for identifying the extent of objects.

- The above figure shows some examples of the localization performance.

- A slightly different bounding box selection strategy is used here.
- Select two bounding boxes (one tight and one loose) from the class activation map of the top 1st and 2nd predicted classes and one loose bounding boxes from the top 3rd predicted class.
- This heuristic is a trade-off between classification accuracy and localization accuracy.
- GoogLeNet-GAP with heuristic achieves a top-5 error rate of 37.1% in a weakly-supervised setting, which is surprisingly close to the top-5 error rate of AlexNet (34.2%) in a fully-supervised setting.
3.3. Deep Features for Generic Localization


- The localization maps generated using our CAM technique with GoogLeNet-GAP are informative.
- As shown above, the most discriminative regions tend to be highlighted across all datasets.
- The CAM approach is effective for generating localizable deep features for generic tasks.
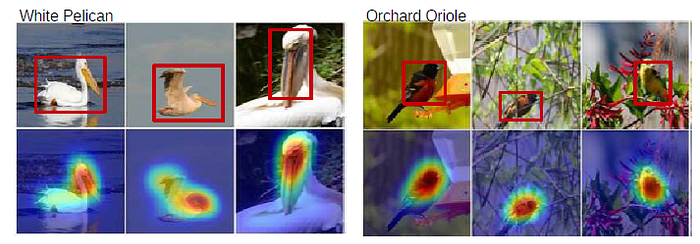
3.4. Fine-grained Recognition

- It is found that GoogLeNet-GAP performs comparably to existing approaches, achieving an accuracy of 63.0% when using the full image without any bounding box annotations for both train and test.
- When using bounding box annotations, this accuracy increases to 70.5%.
- GoogLeNet-GAP is able to accurately localize the bird in 41.0% of the images under the 0.5 intersection over union (IoU) criterion, as compared to a chance performance of 5.5%.
There are still a lot of results not yet shown here. If interested, please feel free to read the paper.
Reference
[2016 CVPR] [CAM]
Learning Deep Features for Discriminative Localization
