[Paper] C3D: Learning Spatiotemporal Features with 3D Convolutional Networks (Video Classification & Action Recognition)
3D Convolutions for Video Classification & Action Recognition
5 min readOct 26, 2020

In this story, Learning Spatiotemporal Features with 3D Convolutional Networks (C3D), by Facebook AI Research, and Dartmouth College, is briefly presented. I read this because this paper comes up when I read a VQA paper, it should be one of the first papers talking about 3D convolution in deep learning. In this paper:
- A deep 3-dimensional convolutional network (3D ConvNet), namely C3D, is trained on multiple tasks and databases, such as video classification and action recognition.
This is a paper in 2015 ICCV with over 3900 citations. (Sik-Ho Tsang @ Medium)
Outline
- 3D Convolution: Difference From 2D Convolution
- C3D: Network Architecture
- Experimental Results
1. 3D Convolution: Difference From 2D Convolution

- (a) & (b): 2D convolution applied on an image will output an image, 2D convolution applied on multiple images (treating them as different channels) also results in an image.
- Hence, 2D ConvNets lose temporal information of the input signal.
- (c): Only 3D convolution preserves the temporal information of the input signals resulting in an output volume.
- With more than 1 filters, let say n filters, the output would be n 3D volumetric outputs.
- A video clip with a size of c×l×h×w where c is the number of channels, l is length in number of frames, h and w are the height and width of the frame, respectively. 3D convolution and pooling kernel sizes are referred by d×k×k, where d is kernel temporal depth and k is kernel spatial size.
2. C3D: Network Architecture
2.1. Network Architecture to Find Optimal Kernel Temporal Depth
- All video frames are resized into 128×171. The input dimensions are 3×16×128×171. Random crops with a size of 3×16×112×112 of the input clips are used during training.
- The networks have 5 convolution layers and 5 pooling layers (each convolution layer is immediately followed by a pooling layer), 2 fully-connected layers and a softmax loss layer to predict action labels.
- The number of filters for 5 convolution layers from 1 to 5 are 64, 128, 256, 256, 256, respectively.
- For the temporal depth, experiments are tried with constant, increasing and decreasing depths, as the below figure.
- The two fully connected layers have 2048 outputs.
- Mini-batches of 30 clips and 16 epoches are used.
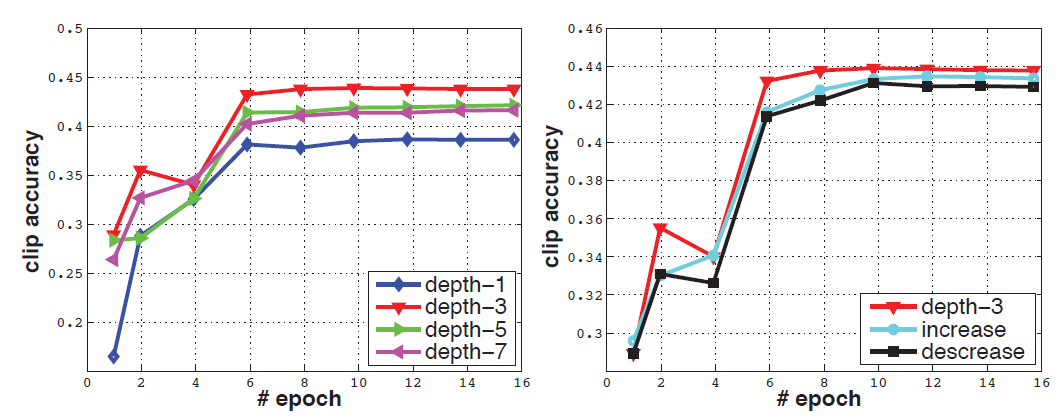
It is found that constant 3×3×3 3D convolutions have the best performance.
2.2. C3D: Network Architecture

- With the GPU memory limitation, a 3D ConvNet is designed to have 8 convolution layers, 5 pooling layers, followed by 2 fully connected layers, and a softmax output layer, namely C3D.
3. Experimental Results
3.1. Video Classification

- Sport-1M consists of 1.1 million sports videos. Each video belongs to one of 487 sports categories.
- The C3D network trained from scratch yields an accuracy of 84.4% and the one fine-tuned from the I380K pre-trained model yields 85.5% at video top-5 accuracy.
- C3D is still 5.6% below the method of [29]. However, this method uses convolution pooling of deep image features on long clips of 120 frames, thus it is not directly comparable. In practice, convolution pooling or more sophisticated aggregation schemes [29] can be applied on top of C3D features to improve video hit performance.

- The deconvolution method explained in ZFNet is used to understand what C3D is learning internally, as shown above.
- The above figure visualizes deconvolution of two C3D conv5b feature maps with highest activations projected back to the image space.
Interestingly, C3D captures appearance for the first few frames but thereafter only attends to salient motion.
3.2. Action Recognition
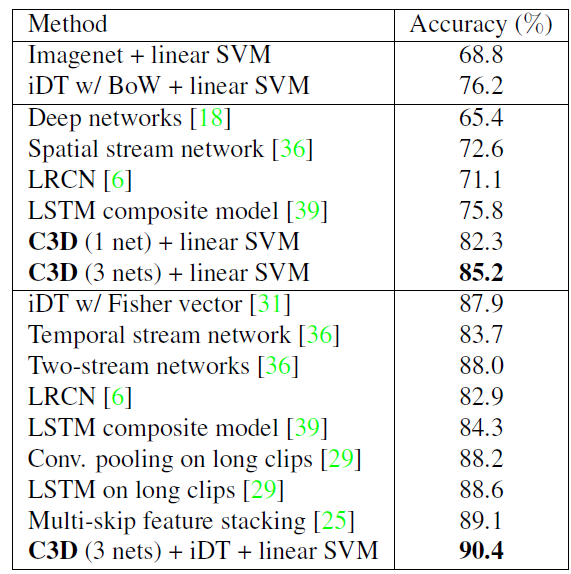
- UCF101 consists of 13.320 videos of 101 human action categories.
- The upper part shows results of the two baselines. The middle part presents methods that use only RGB frames as inputs. And the lower part reports all current best methods using all possible feature combinations (e.g. optical flows, iDT).
- C3D using one net which has only 4,096 dimensions obtains an accuracy of 82.3%.
- C3D with 3 nets boosts the accuracy to 85.2% with the dimension is increased to 12,288.
3.3. Action Similarity Labeling

- The ASLAN dataset consists of 3,631 videos from 432 action classes. The task focuses on predicting action similarity not the actual action label.
- C3D significantly outperforms state-of-the-art method [45] by 9.6% on accuracy and 11.1% on area under ROC curve (AUC).
- Imagenet baseline performs reasonably well which is just 1.2% below state-of-the-art method [45], but 10.8% worse than C3D due to lack of motion modeling.
3.4. Runtime Analysis
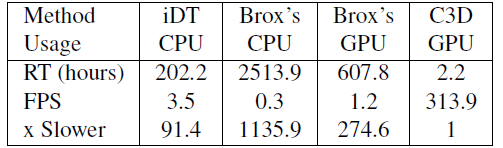
- C3D is much faster than real-time, processing at 313 fps while the other two methods have a processing speed of less than 4 fps.
Reference
[2015 ICCV] [C3D]
Learning Spatiotemporal Features with 3D Convolutional Networks
Video Classification
[C3D]
