[Paper] DeepIQA: DIQaM & WaDIQaM Weighted Average Deep Image QuAlity Measure (Image Quality Assessment)
Network Inspired by VGGNet, Can Be Used In Both FR and NR IQA.

In this story, “Deep Neural Networks for No-Reference and Full-Reference Image Quality Assessment” (DeepIQA: DIQaM & WaDIQaM), by Berlin Institute of Technology, Korea University, the Max Planck Institute for Informatics, and Fraunhofer Heinrich Hertz Institute (HHI), is briefly presented. The authors are very famous in the field of video coding as I have read a lot of their papers already. This paper is introduced by my colleague when I recently study/work on Image Quality Assessment (IQA). In this paper:
- For full reference IQA (FR-IQA), a siamese network using CNN is used with both original and distorted images as input. The networks are called DIQaM-FR and WaDIQaM-FR depending on the use of weighted average or not.
- The network comprises ten convolutional layers and five pooling layers for feature extraction, and two fully connected layers for regression, which makes it significantly deeper than related IQA models at that moment.
- For no reference IQA, (NR-IQA), one branch of siamese network is discarded where only the distorted image is used as input. The networks are called DIQaM-NR and WaDIQaM-NR.
- The method is called DeepIQA in GitHub.
This is a paper in 2018 TIP with over 300 citations where TIP has with high impact factor of 6.79. (Sik-Ho Tsang @ Medium)
Outline
- FR-IQA (DIQaM-FR and WaDIQaM-FR)
- NR-IQA (DIQaM-NR and WaDIQaM-NR)
- Experimental Results
1. FR-IQA (DIQaM-FR and WaDIQaM-FR)

1.1. Inputs
- The images are subdivided into 32×32 sized patches that are input to the neural network. Local patchwise qualities are pooled into a global imagewise quality estimate by simple or weighted average patch aggregation.
- The inputs are the reference/original patch and the distorted patch.
- The aim is to predict the image quality score for the distorted patch given also the reference patch.
1.2. Feature Extraction
- The inputs are processed in parallel by two networks sharing their synaptic connection weights.
- The network uses 3×3 convolutions, which is inspired by VGGNet. ReLU is used. 2×2 max pooling is used.
- After feature extraction, feature vector fr is obtained from the reference patch. Similar for the feature vector fd, it is obtained from the distorted patch.
1.3. Feature Fusion
- Then, feature vector fr-fd is obtained. The difference can be a meaningful representation for distance in feature space.
- The above 3 feature vectors are concatenated.
1.3. Regression
- The fused features are regressed to a patchwise quality estimate by a sequence of one FC-512 and one FC-1 layer. This results in about 5.2 million trainable network parameters.
1.4. Spatial Pooling (DIQaM-FR)
- The simplest way to pool locally estimated visual qualities yi to a global image-wise quality estimate ˆq is to assume identical relative importance of every image region:

- where Np denotes the number of patches sampled from the image.
- During training, MAE is used as loss function:

- However, spatial pooling by averaging local quality estimates does not consider the effect of spatially varying perceptual relevance of local quality.
1.5. Pooling by Weighted Average Patch Aggregation (WaDIQaM-FR)
- A second branch is integrated into the regression module of the network that runs in parallel to the patchwise quality regression branch, as shown in the dotted box of the above figure.
- This branch outputs a weight αi* for a patch i.
- An the global image quality estimate ˆq can be calculated as:
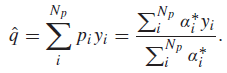
- During training, the loss function is:
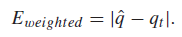
2. NR-IQA (DIQaM-NR and WaDIQaM-NR)

- As shown above, abolishing the branch that extracts features from the reference patch from the Siamese network is a straightforward approach.
- As no features from the reference patch are available anymore, no feature fusion is necessary.
- However, both pooling methods mentioned in FR-IQA are applicable for NR-IQA as well.
- Same loss functions are also used as for the FR IQA case.
- In order to train all methods as similar as possible, each mini-batch contains 4 images, each represented by 32 randomly sampled image patches which leads to the effective batch size of 128 patches.
3. Experimental Results
3.1. Performance Comparison on LIVE and TID2013

- For evaluation, prediction accuracy is quantified by Pearson linear correlation coefficient (LCC), prediction monotonicity is measured by Spearman rank order coefficient (SROCC).
- FR-IQA: The proposed approach obtains superior performance to state-of-the-art on LIVE, except for DeepSim evaluated by SROCC.
- NR-IQA: The proposed model employing simple average pooling (DIQaM-NR) performs best in terms of LCC among all methods evaluated, and in terms of SROCC performs slightly worse than SOM.
- In contrast to our FR IQA models for NR IQA the weighted average patch aggregation pooling decreases the prediction performance.
3.2. Performance Comparison on Different Subsets of TID2013
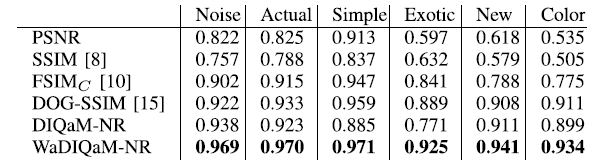
- While DIQaM-FR performs comparable to the state-of-the-art method, on some groups better, on some worse,WaDIQaM-FR shows superior performance for all grouped distortion types.
3.3. Performance Comparison of NR IQA on CLIVE

- CLIVE is a challenging dataset.
- WaDIQaM-NR shows prediction performance superior to most other models, but is clearly outperformed by FRIQUEE.
- Interestingly and contrasting to the results on LIVE and TID2013, on CLIVE WaDIQaM-NR performs clearly better than DIQaM-NR.
There are still a lot of analyses and results for the proposed approach. If interested, please feel free to read the paper.
References
[2018 TIP] [DeepIQA]
Deep neural networks for no-reference and full-reference image quality assessment
[GitHub] https://github.com/dmaniry/deepIQA
