[Paper] MorphNet: Fast & Simple Resource-Constrained Structure Learning of Deep Networks (Image Classification)
Shrink & Expand to Improve the Networks: Inception-v2, ResNet & MobileNetV1

In this story, MorphNet: Fast & Simple Resource-Constrained Structure Learning of Deep Networks (MorphNet), by Google AI, Google Brain, Energy-efficient multimedia systems group, MIT, and, Georgia Institute of Technology, is briefly presented. In this paper:
- A simple and general technique for a resource-constrained optimization of DNN architectures which is adaptable to specific resource constraints (e.g. FLOPs), and capable of increasing the network’s performance.
- First, shrink an existing model such as ResNet using sparsifying regularizer. Then, expand all layers uniformly with width multiplier.
- With the above shrink & expand process performed iteratively, the network is shrunken with improved performance.
This is a paper in 2018 CVPR with over 100 citations. (Sik-Ho Tsang @ Medium)
Outline
- Naive Solution: Simply Using Width Multiplier
- MorphNet: Shrink & Expand
- Experimental Results
1. Naive Solution: Simply Using Width Multiplier
- Assume we already got a network where O1:M are the output widths of all layers, and we want to have a constraint on the network, e.g.: fewer FLOPs, or smaller model size.
- According to the constraint, we would like to shrink the network to fit the constraint while having the smallest loss by the network:

- where the constraint is denoted by F(O1:M) ≤ ζ for F monotonically increasing in each dimension, F is either the number of FLOPs per inference or the model size (i.e., number of parameters).
- One naive solution is to find the largest w such that F(w · O1:M) ≤ ζ, where w is the width multiplier which can be smaller than one when we want to shrink the network. (If it is larger than one, the network is expanded.)
- (This approach is used in many papers to increase the size of network to a similar network size of other SOTA models, for fair comparison.)
- In most cases the network, i.e. the form of F, allows for easily finding the optimal w.
- Despite its simplicity, this approach suffers, however, with decreased quality of the initial network design.
2. MorphNet: Shrink & Expand

2.1. Shrink (Steps 1 & 2)
- In the shrinking phase, MorphNet identifies inefficient neurons and prunes them from the network by applying a sparsifying regularizer G(θ) such that the total loss function of the network includes a cost for each neuron.
- Suppose a layer has 6 weights from a to f.

- Left: If c and f are set as zero, the network cannot be shrunk.
- Middle: But if e and f are set as zero, the network can be shrunk to as the Right one. In this paper, this is done by Group Lasso regularizer.
- Unlike the width multiplier approach, this approach is able to change the relative sizes of layers.
For example, when targeting FLOPs, higher-resolution neurons in the lower layers of the DNN tend to be sacrificed more than lower-resolution neurons in the upper layers of the DNN.
The situation is the exact opposite when the targeted resource is model size rather than FLOPs.
2.2. Expand (Step 3)
- During expansion, a simple method is used only, namely uniformly expanding all layer sizes via a width multiplier as much as the constrained resource allows.
2.3. Iteration of Step 1–3 (Step 4)
- Thus, the above completed one cycle of improving the network architecture.
- We can continue this process iteratively until the performance is satisfactory, or until the DNN architecture has converged (i.e., further iterations lead to a near-identical DNN structure).
- Yet, it is found a single iteration of Steps 1–3 to be enough to yield a noticeable improvement over the naive solution of just using a uniform width multiplier, while subsequent iterations can bring additional benefits in.
2.4. ResNet & Inception-v2 As Examples
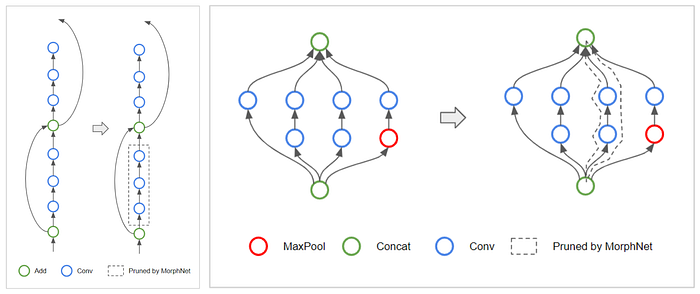
- When a layer has 0 neurons, this effectively changes the topology of the network by cutting the affected branch from the network.
- Left: For ResNet, MorphNet might keep the skip-connection but remove the residual block as shown below (left).
- Right: For Inception-v2, MorphNet might remove entire parallel towers as shown on the right.
- To do this, Group Lasso is used as the regularizer. (CondenseNet has also used Group Lasso to “condense” the network.)

- The FLOP regularizer primarily prunes the early, compute-heavy layers. It notably learns to remove whole layers to further reduce computational burden.
- By contrast, the model size regularizer focuses on removal of 3×3 convolutions at the top layers as those are the most parameter-heavy.
- (There are more detailed explanation/equations for the regularizer in the paper. If interested, please feel free to read the paper.)
3. Experimental Results
3.1. Study on MorphNet

- Using MorphNet approach (Blue) has better performance than just using naive width multiplier (Red).
- Pentagon: Re-expanding one of the networks induced by the FLOP regularizer.
- Star point: Performing the sparsifying and expanding process a second time.
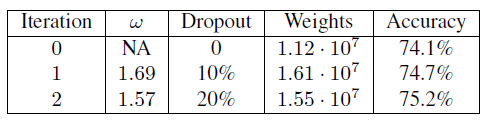
- With more iterations, the accuracy is improved.
- (Dropout rate was increased to mitigate overfit caused by the increased model capacity.)
3.2. Study on Different Models on Different Datasets

- MorphNet can be applied to a variety of datasets and model architectures while maintaining FLOP cost.
- The 1% improvement on MobileNet is especially impressive because MobileNet was specifically hand-designed to optimize accuracy under a FLOPs-constraint.
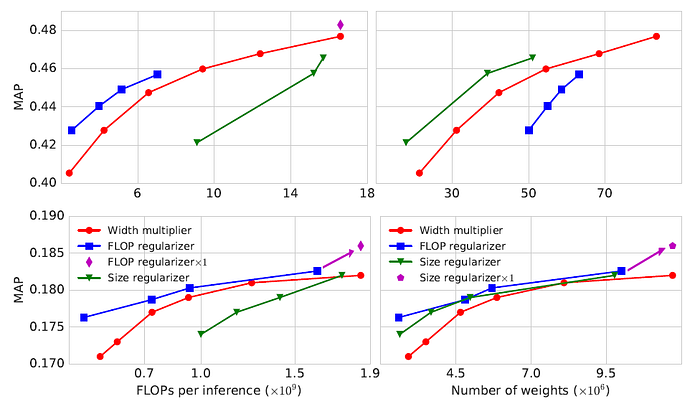
- It is clear that the structures induced when targeting FLOPs form a better FLOPs/performance tradeoff curve, but poor model size/performance tradeoff curves, and vice versa when targeting model size.
References
[2018 CVPR] [MorphNet]
MorphNet: Fast & Simple Resource-Constrained Structure Learning of Deep Networks
[Google AI Blog about MorphNet]
https://ai.googleblog.com/2019/04/morphnet-towards-faster-and-smaller.html
Image Classification
[LeNet] [AlexNet] [Maxout] [NIN] [ZFNet] [VGGNet] [Highway] [SPPNet] [PReLU-Net] [STN] [DeepImage] [SqueezeNet] [GoogLeNet / Inception-v1] [BN-Inception / Inception-v2] [Inception-v3] [Inception-v4] [Xception] [MobileNetV1] [ResNet] [Pre-Activation ResNet] [RiR] [RoR] [Stochastic Depth] [WRN] [ResNet-38] [Shake-Shake] [Cutout] [FractalNet] [Trimps-Soushen] [PolyNet] [ResNeXt] [DenseNet] [PyramidNet] [DRN] [DPN] [Residual Attention Network] [DMRNet / DFN-MR] [IGCNet / IGCV1] [Deep Roots] [MSDNet] [ShuffleNet V1] [SENet] [NASNet] [MobileNetV2] [CondenseNet] [IGCV2] [IGCV3] [FishNet] [SqueezeNext] [ENAS] [PNASNet] [ShuffleNet V2] [BAM] [CBAM] [MorphNet] [AmoebaNet] [ESPNetv2] [MnasNet]

