Review — Heart Sound Classification Using Deep Learning Techniques Based on Log-mel Spectrogram
LSTM and CNN Models are Designed for Evaluation
Heart Sound Classification Using Deep Learning Techniques Based on Log-mel Spectrogram
2LSTM+3FC & 3CONV+2FC, by Hung Yen University of Technology and Education, Taichung Veterans General Hospital, Tunghai University, and Feng Chia University
2023 Springer CSSP (Sik-Ho Tsang @ Medium)Heart Sound Classification
==== My Other Paper Readings Are Also Over Here ====
- The heart sound dataset comprises five classes, one normal class and four anomalous classes, namely, Aortic Stenosis, Mitral Regurgitation, Mitral Stenosis, and Murmur in systole.
- First, the heart sound signals are framed to a consistent length and thereafter extract the log-mel spectrogram features.
- Two deep learning models, long short-term memory (LSTM) and convolution neural network (CNN) are proposed to classify heartbeat sounds based on the extracted features.
Outline
- Heart Sound Dataset
- Preprocessing and Feature Extraction
- Deep Learning Models
- Results
1. Heart Sound Dataset
1.1. Motivation of Using Heart Sound
- Imaging diagnosis includes cardiac magnetic resonance imaging (MRI) [18], heart computed tomography (CT scan) [28], and myocardial perfusion imaging [31].
- However, these techniques’ disadvantages involve adequate requirements of modern machinery, professional examiners, and a long duration of the examination.
1.2. Heart Sound Dataset

- This dataset is a public dataset from [8], consists of 1,000 signal samples in.wav format with a sampling frequency of 8 kHz.
- The dataset is divided into five classes, consisting of one normal class (N) and four anomalous classes, Aortic stenosis (AS), Mitral regurgitation (MR), Mitral stenosis (MS), and Mitral valve prolapse (MVP).
- Aortic stenosis (AS) is when the aortic valve is too small, narrow, or stiff. The typical murmur of aortic stenosis is a high-pitched, “diamond-shaped” murmur.
- Mitral regurgitation (MR) is when the heart’s mitral valve does not close properly, allowing blood to flow back to the heart instead of being pumped out. S1 may be low (or sometimes loud) when auscultating the fetal heart. The murmur increases in volume up to S2. A short rumbling mid-diastolic murmur can be heard due to the torrential mitral outflow after S3.
- Mitral stenosis (MS) is when the mitral valve is damaged and cannot fully open. Auscultation of heart sounds will reveal an accentuated S1 early in mitral stenosis and soft S1 in severe mitral stenosis. As pulmonary hypertension develops, the S2 sound will be emphasized. A left ventricular S3 is almost always absent in pure MS.
- Mitral valve prolapse (MVP) is the prolapse of the mitral leaflets into the left atrium during systole. MVP is usually benign, but complications include mitral regurgitation, endocarditis, and chordal rupture. Signs include a mid-systolic click and a late systolic murmur if regurgitation is present.
2. Preprocessing and Feature Extraction
2.1. Preprocessing
- There are different lengths in sound signals. Consequently, data framing is used to fix the sampling rate of each record file.
- The length is cropped so that the sound signal contains at least one complete cardiac cycle but should not be too long as it will increase the data size and processing time. An adult person has 65–75 heartbeats per minute or a cardiac cycle of about 0.8 s [11]. Therefore, the signal samples were cropped to 2.0-s, 1.5-s, and 1.0-s segments.
2.2. Feature Extraction
- The raw waveforms from the heart sound signals were converted into a log-mel spectrogram based on the Discrete Fourier transform (DFT).
- The DFT y(k) of a sound signal is Eq. (1), and the log-mel spectrogram s is defined as Eq. (2).
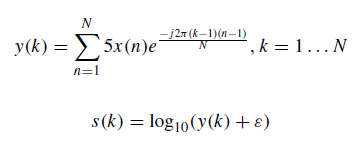
- where, N is the length of vector x, ε = 10^(−6) is a small offset.
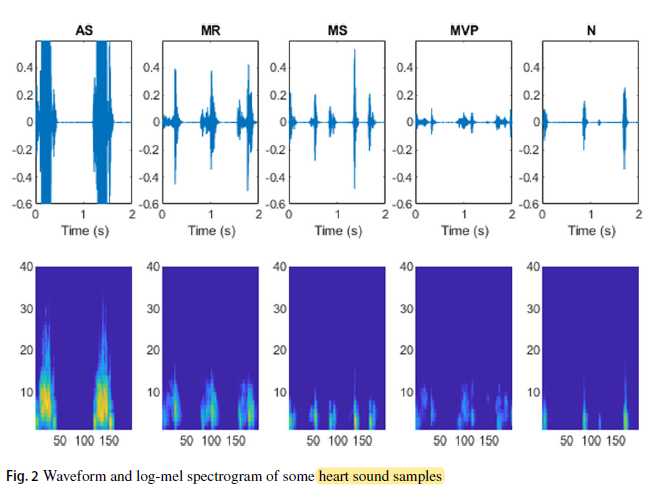
- The waveform and log-mel spectrogram of some heart sound samples:
3. Deep Learning Models
3.1. LSTM Model

- The LSTM model is designed with 2 LSTM layers connected directly, followed by 3 fully connected layers. The third fully connected layer feeds into a softmax classifier.
3.2. CNN Model
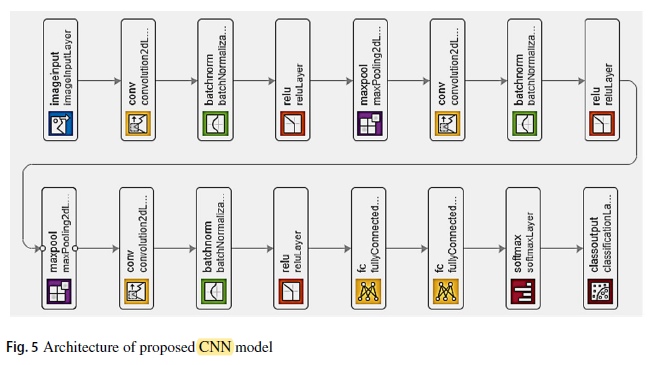
- As shown in Fig. 5, the first two convolutional layers are followed by overlapping max-pooling layers. The third convolutional layer is connected directly to the first fully connected layer. The second fully connected layer feeds into a softmax classifier with five class labels.
- Batch normalization and ReLU are used after each convolutional layer.
3.3. Some Training Details

4. Results
4.1. Precision, Sensitivity, F1 Score, & Accuracy

- The training set contained 70% of the whole dataset, while the testing set contained the rest.
The highest accuracy is 0.9967 with the CNN model segment duration of 2.0 s; the lowest accuracy is 0.9300 with the LSTM model classified and segment duration of 1.0 s.

- The CNN model’s overall accuracy is 0.9967, 0.9933, and 0.9900, respectively, with the segment duration of 2.0 s, 1.5 s, and 1.0 s, while these amounts of the LSTM model are 0.9500, 0.9700, and 0.9300, respectively.
CNN model gave a more accurate prediction than the LSTM model in all segment durations.
4.2. Confusion Matrix
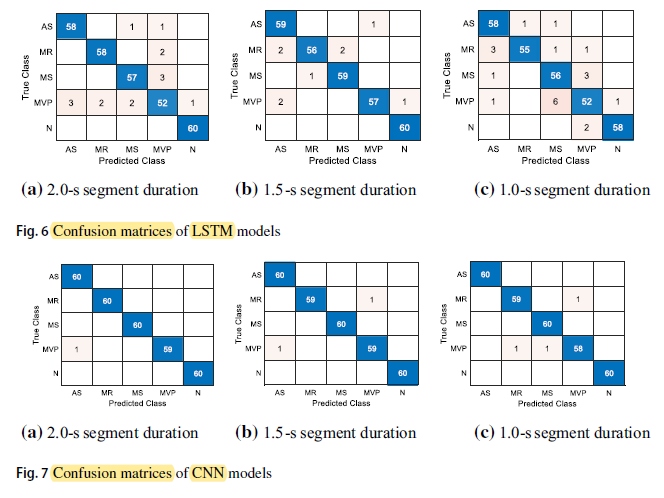
Class N (Normal) had the highest number of correct predictions, reaching 60 among 60 in five cases, while class MVP had the lowest number of correct predictions of all cases.
4.3. Time Measurement

The longest prediction time is 9.8631 ms with the LSTM model segment duration of 2.0 s; the shortest prediction time is 4.2686 ms with the CNN model classified with a segment duration of 1.0 s.
4.4. Model Size
The number of activations and total learnable of the CNN model is larger, 357,950 and 1,624,125, respectively, compared to the LSTM model of 458 and 174,605.
4.5. SOTA Comparisons
- Some studies have very high accuracy [15, 19] and [30] approximate this study, but these studies only performed two classes (normal and abnormal) while this study classified five classes.
Compared to other studies using the same dataset [21] and [33], both of these studies have an accuracy of 0.9700, showing that the proposed research has improved significantly, reaching the highest accuracy of 0.9967.
