Review — PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model
PersonLab, for Human Pose Estimation & Person Instance Segmentation

PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model,
PersonLab, by Google Research,
2018 ECCV, Over 500 Citations (Sik-Ho Tsang @ Medium)
Human Pose Estimation, Keypoint Detection, Instance Segmentation
- First, PersonLab learns to detect individual keypoints and group keypoints into person pose instances.
- Then, it performs semantic segmentation, and associates semantic person pixels with their corresponding person instance, delivering instance-level person segmentations.
Outline
- Overall Architecture
- Person Keypoint Detection
- Person Instance Segmentation
- Results
1. Overall Architecture
- (For quick read, please read sections 1 and 4.)

- PersonLab predicts (1) keypoint heatmaps, (2) short-range offsets, (3) mid-range pairwise offsets, (4) person segmentation maps, and (5) long-range offsets.
- The first three predictions are used by the Pose Estimation Module in order to detect human poses while the latter two, along with the human pose detections, are used by the Instance Segmentation Module in order to predict person instance segmentation masks, as above.
2. Person Keypoint Detection
2.1. Heatmap Prediction

- DR(y) is a disk area of radius R=32 centered around y.
- For every keypoint type k=1, …, K, a binary classification task is set up as follows. A heatmap pk(x) such that pk(x)=1 if x ∈ DR(yj, k) for any person instance j, otherwise pk(x) = 0.
- The heatmap loss is the average logistic loss.
2.2. Short-Range Offsets Prediction

Short-range offset vectors Sk(x) are also predicted to improve the keypoint localization accuracy.
- At each position x within the keypoint disks and for each keypoint type k, the short-range 2-D offset vector Sk(x) = yj,k − x points from the image position x to the k-th keypoint of the closest person instance j.
- L1 loss is used within the keypoint disks wirh R=32.
2.3. Hough Score Maps

- The heatmap and short-range offsets are aggregating via Hough voting into 2-D Hough score maps hk(x) where k from 1 to K.
- Each image position casts a vote to each keypoint channel k with weight equal to its activation probability:
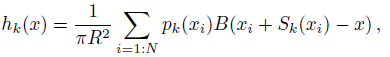
- where B(·) is bilinear interpolation.
This local maxima in the score maps hk(x) serve as candidate positions for person keypoints, yet they carry no information about instance association.
2.4. Grouping keypoints into person detection instances
- (There are highly details here, but many steps are described in sentences in the paper. It is better to read their GitHub for more understanding if needed.)
2.4.1. Mid-Range Pairwise Offsets

- A separate pairwise mid-range 2-D offset field output Mk,l(x) designed to connect pairs of keypoints, is added.
- The supervised training target for the pairwise offset field from the k-th to the l-th keypoint is given by:
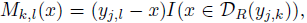
- The L1 loss is used for the regression prediction.
2.4.2. Recurrent Offset Refinement
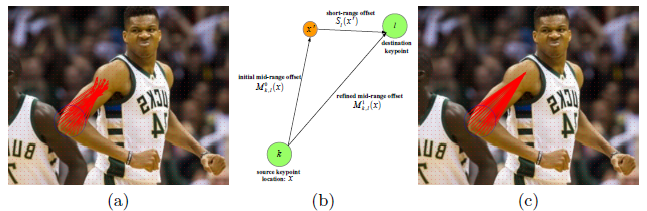
- However, keypoints such as RightElbow and RightShoulder which may be several hundred pixels away in the image, making it hard to generate accurate regressions.
- The mid-range pairwise offsets are recurrently refined using the more accurate short-range offsets:
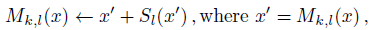
- This refinement step is performed twice.
2.4.3. Fast Greedy Decoding
- It groups keypoints into detected person instances.
- A priority queue is created, shared across all K keypoint types, in which there are the position xi and keypoint type k of all local maxima in the Hough score maps hk(x).
- The edges of the kinematic person graph to greedily connect pairs (k, l) of adjacent keypoints:
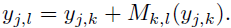
- Previously detected person instances are rejected using NMS of r=10.
2.4.4. Keypoint- and Instance-Level Detection Scoring

- Consider a detected person instance j with keypoint coordinates yj,k. Let λj be the square root of the area of the bounding box tightly containing all detected keypoints of the j-th person instance.
- The Expected-OKS score for the k-th keypoint is:
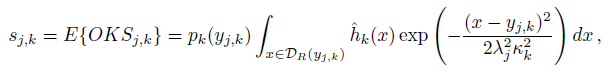
- where ˆhk(x) is the Hough score normalized in DR(yj,k).
- The instance-level score is the average of the keypoint scores. Thus, the final instance-level score is the sum of the scores of the keypoints that have not already been claimed by higher scoring instances, normalized by the total number of keypoints:
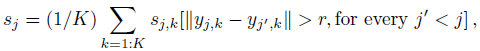
where r=10 is the NMS-radius.
3. Person Instance Segmentation
- (There are highly details here, but many steps are described in sentences in the paper. It is better to read their GitHub for more understanding if needed.)

- Given the set of keypoint-level person instance detections, the task of segmentation stage is to identify pixels that belong to people (recognition) and associate them with the detected person instances (grouping).
3.1. Semantic person segmentation
- A simple semantic segmentation head is used, which consists of a single 1×1 convolutional layer that performs dense logistic regression.
- (b): At each image pixel xi, the probability pS(xi) that it belongs to at least one person is computed. Average logistic loss is used.
3.2. Associating Segments with Instances via Geometric Embeddings
- At each image position x inside the segmentation mask of instance j, the long-range offset vector Lk(x) = yj,k − x is computed, which points from the image position x to the position of the k-th keypoint of the corresponding instance j. (This is very similar to the short-range prediction task.)
- L1 loss is used.
- The long-range offsets are recurrently refined, twice by themselves and then twice by the short-range offsets.
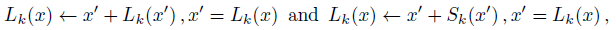
- (c): The long-range vector field effectively partitions the image plane into basins of attraction for each person instance.
- The embedding representation for instance association task is defined as the 2 · K dimensional vector G(x) = (G_k(x)) where k=1,…,K with components Gk(x) = x + Lk(x).
- To decide if the person pixel xi belongs to the j-th person instance, the embedding distance metric is computed:
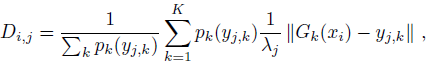
- where yj,k is the position of the k-th detected keypoint in the j-th instance and pk(yj,k) is the probability that it is present.
- (d) The final instance segmentation result: (1) all positions xi marked as person in the semantic segmentation map, i.e. those pixels that have semantic segmentation probability pS(xi) ≥ 0.5 are found. (2) Then, each person pixel xi is associated with every detected person instance j for which the embedding distance metric satisfies Di,j ≤ t; where the relative distance threshold t=0.25.
4. Results
4.1. COCO Person Keypoints

On COCO test-dev. PersonLab single-scale inference result is already better than the results of the CMU-Pose and Associative Embedding [2] bottom-up methods, even when they perform multi-scale inference.
PersonLab also outperforms top-down methods like Mask R-CNN and G-RMI.
- The best result of PersonLab is with 0.687 AP, attained with a ResNet-152 based model and multi-scale inference. This result is still behind the winners of the 2017 keypoints challenge (Megvii) [37] with 0.730 AP, but they used a carefully tuned two-stage, top-down model that also builds on a significantly more powerful CNN backbone.
4.2. COCO Person Instance Segmentation
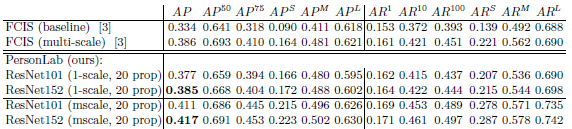
- On the test split, PersonLab outperforms FCIS in both single-scale and multi-scale inference settings.
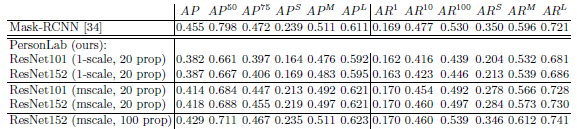
PersonLab performance on the val split is similar to that of Mask R-CNN on medium and large person instances, but worse on small person instances.
- However, it is emphasized that PersonLab is the first box-free, bottom- up instance segmentation method to report experiments on the COCO instance segmentation task.
4.3. Visualizations

- Some person pose and instance segmentation results are visualized above.
Reference
[2018 ECCV] [PersonLab]
PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model
1.6. Instance Segmentation
2014–2018 … [PersonLab] 2020 [Open Images] 2021 [PVT, PVTv1] [Copy-Paste] 2022 [PVTv2] [YOLACT++]
1.9. Human Pose Estimation
2014–2015 [DeepPose] [Tompson NIPS’14] [Tompson CVPR’15] 2016 [CPM] [FCGN] [IEF] [DeepCut & DeeperCut] [Newell ECCV’16 & Newell POCV’16] 2017 [G-RMI] [CMUPose & OpenPose] [Mask R-CNN] 2018 [PersonLab]
