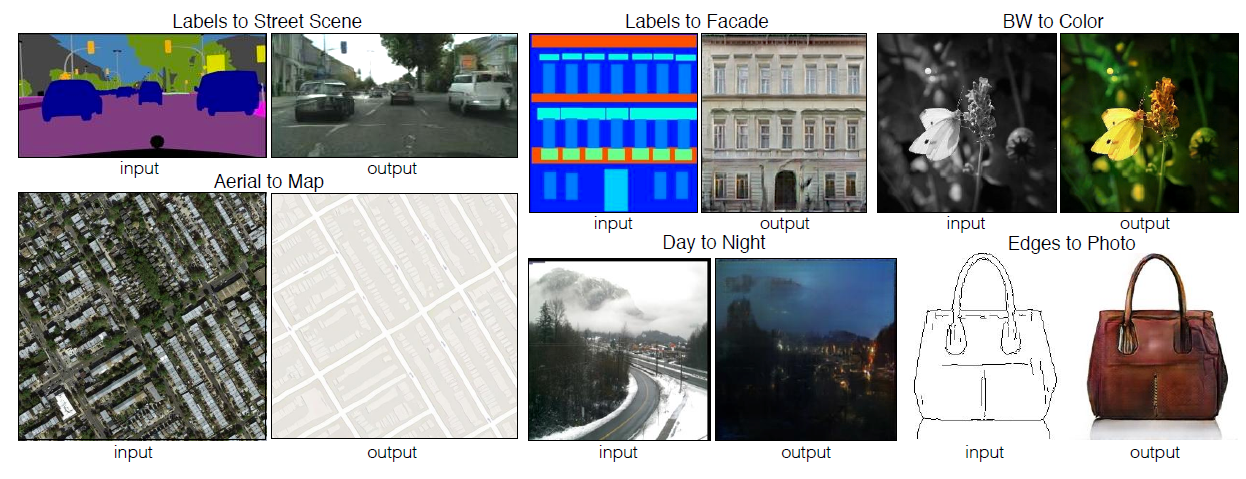
In this story, Image-to-Image Translation with Conditional Adversarial Networks, Pix2Pix, by Berkeley AI Research (BAIR) Laboratory, UC Berkeley, is presented. In this paper:
- Conditional adversarial networks are investigated as a general-purpose solution to image-to-image translation problems.
- These networks not only learn the mapping from input image to output image, but also learn a loss function to train this mapping.
- This approach is effective at synthesizing photos from label maps, reconstructing objects from edge maps, and colorizing images, among other tasks.
This is a paper in 2017 CVPR with over 7000 citations. (Sik-Ho Tsang @ Medium)
There is a funny online demo for Pix2Pix: https://affinelayer.com/pixsrv/
Outline
- Brief Review of CGAN
- Pix2Pix: Loss Function
- Pix2Pix: Network Architectures
- Pix2Pix: PatchGAN
- Experimental Results
1. Brief Review of CGAN

- The above shows an example of training a conditional GAN to map edges→photo.
- The discriminator, D, learns to classify between fake (synthesized by the generator) and real {edge, photo} tuples.
- The generator, G, learns to fool the discriminator.
- Unlike an unconditional GAN, both the generator and discriminator observe the input edge map.

That is, conditional GANs learn a mapping from observed image x and random noise vector z, to y.
2. Pix2Pix: Loss Function
2.1. Loss Function
- The objective of a conditional GAN (CGAN) can be expressed as

- To test the above importance of conditioning the discriminator, an unconditional variant is also tried:

- For the generator, it is tasked to not only fool the discriminator but also to be near the ground truth output in an L2 sense. But, L1 distance is used rather than L2 as L1 encourages less blurring:
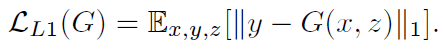
- The final objective is:
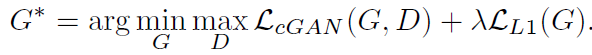
- Without z, the net could still learn a mapping from x to y, but would produce deterministic outputs,
- In Pix2Pix, for the final models, noise is only provided in the form of dropout, applied on several layers of the generator at both training and test time.
2.2. Training & Inference
- Alternate training is applied between one gradient descent step on D, then one step on G.
- As suggested in the original GAN paper, rather than training G to minimize log(1-D(x, G(x, z)), instead, train to maximize log D(x, G(x, z)).
- The objective is divided by 2 while optimizing D, which slows down the rate at which D learns relative to G.
- At inference time, the generator net is run in exactly the same manner as during the training phase.
- Batch normalization is applied using the statistics of the test batch.
3. Pix2Pix: Network Architectures

- Both generator and discriminator use modules of the form convolution-BatchNorm-ReLu.
- In such a network, the input is passed through a series of layers that progressively downsample, until a bottleneck layer, at which point the process is reversed.
- For many image translation problems, there is a great deal of low-level information shared between the input and output, and it would be desirable to shuttle this information directly across the net.
- Thus, U-Net-like architecture is used.
4. Pix2Pix: PatchGAN
- L1 term is to force low-frequency correctness. In order to model high-frequencies, it is sufficient to restrict the attention to the structure in local image patches.
- A discriminator architecture is designed, so called PatchGAN, that only penalizes structure at the scale of patches.
- This discriminator tries to classify if each N×N patch in an image is real or fake.
- N can be much smaller than the full size of the image and still produce high quality results. This is advantageous because a smaller PatchGAN has fewer parameters, runs faster, and can be applied to arbitrarily large images.
- Such a discriminator effectively models the image as a Markov random field (MRF), assuming independence between pixels separated by more than a patch diameter.
- Therefore, the PatchGAN can be understood as a form of texture/style loss.
5. Experimental Results
5.1. Analysis of Objective Functions

- L1 alone leads to reasonable but blurry results.
- The CGAN alone gives much sharper results but introduces visual artifacts on certain applications.

- “FCN-score” evaluation is used. if the generated images are realistic, classifiers trained on real images will be able to classify the synthesized image correctly as well. In the paper, FCN-8s is used.
- The GAN-based objectives achieve higher scores, indicating that the synthesized images include more recognizable structure.

- The plots show the marginal distributions over output color values in Lab color space.
- It is apparent that L1 leads to a narrower distribution than the ground truth, confirming the hypothesis that L1 encourages average, grayish colors.
- Using a CGAN, on the other hand, pushes the output distribution closer to the ground truth.
5.2. Analysis of Generator Architecture


- The encoder-decoder is unable to learn to generate realistic images.
- Adding skip connections to an encoder-decoder to create a “U-Net” results in much higher quality results.
5.3. From PixelGANs to PatchGANs to ImageGANs


- The bus become red when using PixelGAN loss.
- Using a 16×16 PatchGAN is sufficient to promote sharp outputs, and achieves good FCN-scores, but also leads to tiling artifacts.
- The 70×70 PatchGAN alleviates these artifacts and achieves slightly better scores.
- Scaling beyond this, to the full 286×286 ImageGAN, does not appear to improve the visual quality of the results, and in fact gets a considerably lower FCN-score.

- An advantage of the PatchGAN is that a fixed-size patch discriminator can be applied to arbitrarily large images.
- After training a generator on 256×256 images, test it on 512×512 images, as shown above.
5.4. Perceptual Validation



- AMT Perceptual studies are performed. Turkers were presented with a series of trials that pitted a “real” image against a “fake” image generated by our algorithm.
- 50 Turkers evaluated each algorithm.
- E.g. for colorization, with L1+CGAN loss, it fooled participants on 22.5% of trials while it is still low compared with [62], but [62] is designed specifically for colorization task.
5.5. Semantic Segmentation


- Interestingly, CGANs, trained without the L1 loss, are able to solve this problem at a reasonable degree of accuracy.
- To authors’ knowledge, this is the first demonstration of GANs successfully generating “labels”.
- But simply using L1 regression gets better scores than using a CGAN.
5.6. Community-Driven Research


- There are other applications, e.g. Background removal, Palette generation, Sketch > Portrait, Sketch > Pokemon, ”Do as I Do” pose transfer, Learning to see: Gloomy Sunday.
Reference
[2017 CVPR] [Pix2Pix]
Image-to-Image Translation with Conditional Adversarial Networks
Generative Adversarial Network (GAN)
Image Synthesis [GAN] [CGAN] [LAPGAN] [DCGAN] [Pix2Pix]
Super Resolution [SRGAN & SRResNet] [EnhanceNet] [ESRGAN]
Video Coding [VC-LAPGAN]
