Review — RotNet: Unsupervised Representation Learning by Predicting Image Rotations
RotNet: Self-Supervised Learning by Predicting Image Rotations

In this story, Unsupervised Representation Learning by Predicting Image Rotations, by University Paris-Est, is reviewed. In this paper:
- Using RotNet, image features are learnt by training ConvNets to recognize the 2d rotation that is applied to the image that it gets as input.
- By this mean, unsupervised pre-trained AlexNet model achieves the state-of-the-art mAP of 54.4% that is only 2.4 points lower from the supervised AlexNet.
This is a paper in 2018 ICLR with over 1100 citations. (Sik-Ho Tsang @ Medium)
Outline
- RotNet: Image Rotation Prediction Framework
- Ablation Study & SOTA Comparison on CIFAR-10
- Task Generalization on ImageNet, Places, & PASCAL VOC
1. Image Rotation Prediction Framework

- Given four possible geometric transformations, the 0, 90, 180, and 270 degrees rotations, a ConvNet model F(:) is trained to recognize the rotation that is applied to the image that it gets as input.
- Fy(Xy) is the probability of rotation transformation y predicted by model F(:) when it gets as input an image that has been transformed by the rotation transformation y.
To successfully predict the rotation of an image, the ConvNet model must necessarily learn to localize salient objects in the image, recognize their orientation and object type, and then relate the object orientation with the dominant orientation that each type of object tends to be depicted within the available images.

- The above attention maps are computed based on the magnitude of activations at each spatial cell of a convolutional layer and essentially reflect where the network puts most of its focus in order to classify an input image.
- Both supervised and self-supervised models seem to focus on roughly the same image regions.
2. Ablation Study & SOTA Comparison on CIFAR-10
2.1. Supervised Training on Each Layer on CIFAR

- The RotNet models with Network-In-Network (NIN) architectures are used. The total number of conv. layers of the examined RotNet models is 9, 12, and 15 for 3, 4, and 5 conv. blocks respectively.
- The classifiers are learnt on top of conv layers. Those classifiers are trained in a supervised way on CIFAR-10. They consist of 3 fully connected layers; the 2 hidden layers have 200 feature channels each and are followed by batch-norm and ReLU units.
- AlexNet or NIN is used as the ConvNet depending on the tasks.
In all cases, the feature maps generated by the 2nd conv. block (that actually has depth 6 in terms of the total number of conv. layer till that point) achieve the highest accuracy, i.e., between 88.26% and 89.06%.
Increasing the total depth of the RotNet models leads to increased object recognition performance by the feature maps generated by earlier layers.
2.1. Number of Rotations

- The 2 orientations case offers too few classes for recognition.
- The 8 orientations case the geometric transformations are not distinguishable enough and furthermore the 4 extra rotations introduced may lead to visual artifacts on the rotated images.
The best one is the one using 4 rotations of 0, 90, 180, and 270.
2.3. SOTA Comparison

- RotNet improves over the prior unsupervised approaches such as Exemplar-CNN and DCGAN, and achieve state-of-the-art results in CIFAR-10.
More notably, the accuracy gap between the RotNet based model and the fully supervised NIN model is very small, only 1.64 percentage points (92.80% vs 91.16%).
3. Task Generalization on ImageNet, Places, & PASCAL VOC
3.1. ImageNet

RotNet surpasses all the other methods, such as Context Prediction, Colorization, Jigsaw Puzzles, and BiGAN, by a significant margin.
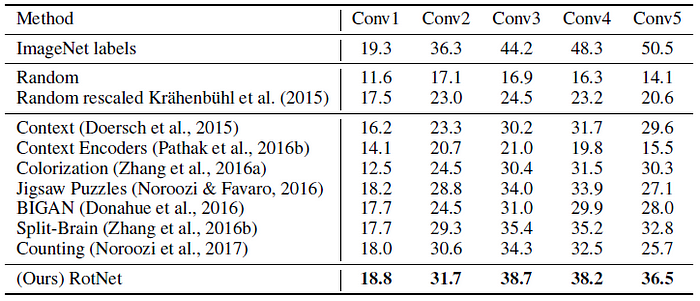
- Regression classifiers on top of the feature maps of each layer are trained to perform the 1000-way ImageNet classification task.
- All weights are frozen and feature maps are spatially resized (with adaptive max pooling) so as to have around 9000 elements.
- All approaches use AlexNet variants and were pre-trained on ImageNet without labels except “ImageNet labels”.
Again, RotNet demonstrates significant improvements over prior unsupervised methods, such as Context Prediction, Context Encoders, Colorization, Jigsaw Puzzles, Split-Brain Auto, and BiGAN.
3.2. Places
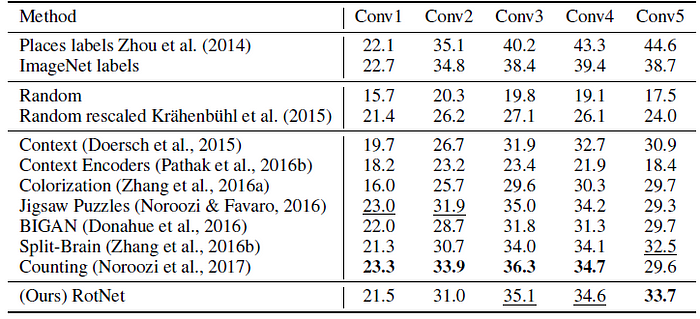
Similarly, RotNet manages to either surpass or achieve comparable results w.r.t. prior state-of-the-art unsupervised learning approaches, , such as Context Prediction, Context Encoders, Colorization, Jigsaw Puzzles, Split-Brain Auto, and BiGAN.
3.3. PASCAL VOC
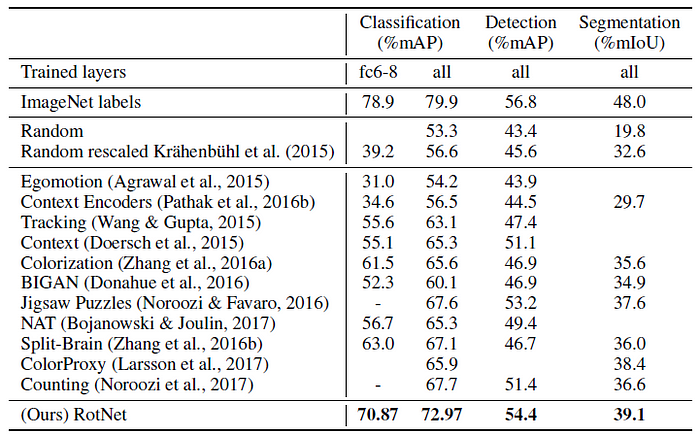
- For classification, the features are either fixed before conv5 (column fc6–8) or the whole model is fine-tuned (column all). For detection multi-scale training and single scale testing are used. All approaches use AlexNet variants and were pre-trained on ImageNet without labels.
RotNet outperforms by significant margin all the competing unsupervised methods, such as Context Prediction, Context Encoders, Colorization, Jigsaw Puzzles, Split-Brain Auto, and BiGAN, in all tested tasks, significantly narrowing the gap with the supervised case.
Notably, the PASCAL VOC 2007 object detection performance that our self-supervised model achieves is 54.4% mAP, which is only 2.4 points lower than the supervised case.
Reference
[2018 ICLR] [RotNet/Image Rotations]
Unsupervised Representation Learning by Predicting Image Rotations
Self-Supervised Learning
2008–2010 [Stacked Denoising Autoencoders] 2014 [Exemplar-CNN] 2015 [Context Prediction] 2016 [Context Encoders] [Colorization] [Jigsaw Puzzles] 2017 [L³-Net][Split-Brain Auto] 2018 [RotNet/Image Rotations]
