Review — Stacked Denoising Autoencoders (Self-Supervised Learning)
One of the Earliest Reconstruction-Based Self-Supervised Learning Approaches, Using Denoising Autoencoders/Stacked Denoising Autoencoders

In this story, Extracting and Composing Robust Features with Denoising Autoencoders, (Denoising Autoencoders/Stacked Denoising Autoencoders), by Universite de Montreal, is briefly reviewed. This is a paper by Prof. Yoshua Bengio’s research group. In this paper:
- Denoising Autoencoder is designed to reconstruct a denoised image from a noisy input image.
- By training the denoising autoencoder, feature learning is achieved without using any labels, which is then used for fine-tuning in image classification tasks.
- This paper should be one of the early papers for self-supervised learning.
This is a paper in 2008 ICML with over 5800 citations. And later published in 2010 JMLR with over 6200 citations. (Sik-Ho Tsang @ Medium)
Outline
- Denoising Autoencoder
- Stacked Denoising Autoencoder
- Fine-Tuning for Image Classification
- Experimental Results
1. Denoising Autoencoder

- x: Original input image.
- ~x: Corrupted image.
- y: Hidden representation:

- z: Reconstructed image.

- Autoencoder consists of an encoder and a decoder.
- Encoder: The corrupted input ~x is first mapped to a hidden representation y.
- Decoder: Then the cleaned input z is reconstructed from y.
The above autoencoder only got one layer fθ at encoder, and one gθ at decoder.
2. Stacked Denoising Autoencoder
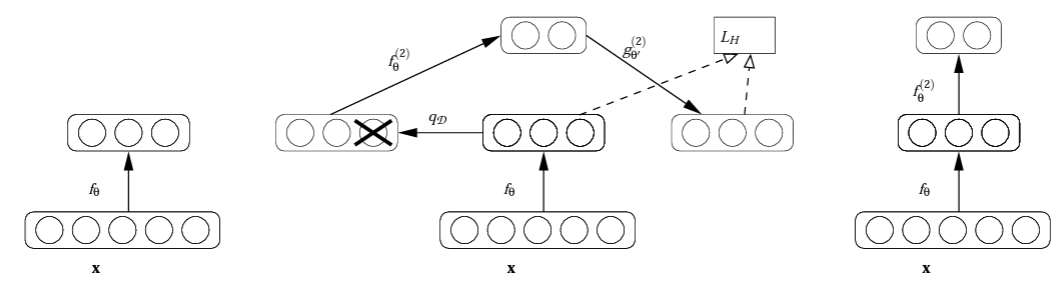
- To train a deep autoencoder, at that time, it was difficult to train. The autoencoder is trained layer-by-layer at that moment.
- Left: After training a first level denoising autoencoder (i.e. fθ in the first figure), its learnt encoding function fθ is used on clean input (left).
- Middle: The resulting representation is used to train a second level denoising autoencoder to learn a second level encoding function f(2)θ.
- Right: From there, the procedure can be repeated to have deeper model.
3. Fine-Tuning for Image Classification

- After training a stack of encoders as explained in the previous figure, an output layer is added on top of the stacked layers of the encoder part.
- The parameters of the whole system are fine-tuned to minimize the error in predicting the supervised target (e.g., class), by performing gradient descent on a supervised cost.
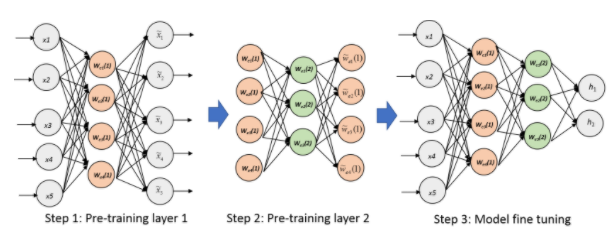
- The above figure shows the general steps for pre-training using autoencoder, and fine-tuning using encoder.
4. Experimental Results


- Different corruptions are added to the dataset for testing.
- rot: Rotation.
- bg-rand: Addition of a background composed of random pixels
- bg-img: Addition of a background composed of patches extracted from a set of image, etc.
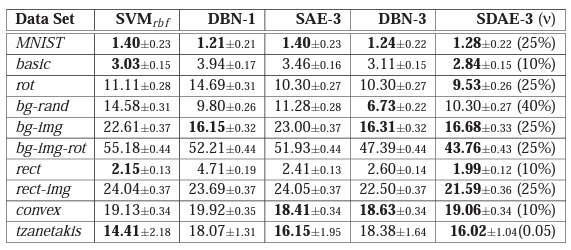
- SDAE-3: Neural networks with 3 hidden layers initialized by stacking denoising autoencoders.
- The encoder part is fine-tuned on the classification tasks.
SDAE-3 algorithm performs on par or better than the best other algorithms, including deep belief nets.
Unsupervised initialization of layers with an explicit denoising criterion helps to capture interesting structure in the input distribution.
This in turn leads to intermediate representations much better suited for subsequent learning tasks such as supervised classification.
References
[2008 ICML] [Denoising Autoencoders]
Extracting and Composing Robust Features with Denoising Autoencoders
[2010 JMLR] [Stacked Denoising Autoencoders]
Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion
Self-Supervised Learning
2008–2010 [Stacked Denoising Autoencoders] 2014 [Exemplar-CNN] 2015 [Context Prediction] 2016 [Context Encoders] 2017 [L³-Net]
