Review — Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation
Swin-Unet, Using Swin Transformer to Construct U-Net
Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation,
Swin-Unet, by Technische Universität München, Fudan University, and Huawei Technologies,
2022 ECCV, Over 600 Citations (Sik-Ho Tsang @ Medium)
Medical Imaging, Medical Image Analysis, Image Segmentation, U-Net, Swin Transformer4.2. Biomedical Image Segmentation
2015 … 2022 [UNETR] [Half-UNet] [BUSIS] [RCA-IUNet] 2023 [DCSAU-Net]
My Other Previous Paper Readings Also Over Here
- Swin-Unet is proposed, which is a U-Net-like pure Transformer for medical image segmentation.
- A hierarchical Swin Transformer with shifted windows as the encoder to extract context features.
- And a symmetric Swin Transformer-based decoder with patch expanding layer is designed to perform the up-sampling operation to restore the spatial resolution of the feature maps.
Outline
- Swin Transformer Block
- Swin-Unet Overall Architecture
- Results
1. Swin Transformer Block

- Two consecutive Swin Transformer blocks are presented.

- Each Swin Transformer block is composed of Layer Norm (LN) layer, multi-head self attention module, residual connection and 2-layer MLP with GELU non-linearity.
- The window-based multi-head self attention (W-MSA) module and the shifted window-based multi-head self attention (SW-MSA) module are applied in the two successive Transformer blocks, respectively.
- (Please feel free to read about Swin Transformer for the shifted window selff attention.)
2. Swin-Unet Overall Architecture

2.1. Encoder
- The input image size and patch size are set as 224×224 and 4.
- The C-dimensional tokenized inputs with the resolution of H/4×W/4 are fed into the two consecutive Swin Transformer blocks to perform representation learning, in which the feature dimension and resolution remain unchanged.
- Meanwhile, the patch merging layer will reduce the number of tokens (2× downsampling) and increase the feature dimension to 2× the original dimension.
- This procedure will be repeated three times in the encoder.
2.2. Patch Merging Layer
- The input patches are divided into 4 parts and concatenated together by the patch merging layer.
- The feature resolution will be down-sampled by 2×. And, since the concatenate operation results the feature dimension increasing by 4×, a linear layer is applied on the concatenated features to unify the feature dimension to the 2× the original dimension.
2.3. Bottleneck
- Only two successive Swin Transformer blocks are used to constructed the bottleneck to learn the deep feature representation.
- The feature dimension and resolution are kept unchanged.
2.4. Decoder
- The symmetric decoder is built based on Swin Transformer block.
- The patch expanding layer in the decoder is used to up-sample the extracted deep features. It reshapes the feature maps of adjacent dimensions into a higher resolution feature map (2× up-sampling) and reduces the feature dimension to half of the original dimension accordingly.
2.5. Patch Expanding Layer
- Before up-sampling, a linear layer is applied on the input features to increase the feature dimension to 2× the original dimension.
- Then, rearrange operation is used to expand the resolution of the input features to 2× the input resolution and reduce the feature dimension to quarter of the input dimension.
2.6. Skip Connection
- The skip connections are used to fuse the multi-scale features from the encoder with the up-sampled features.
- The shallow features and the deep features are concatenated together to reduce the loss of spatial information caused by down-sampling, followed by a linear layer.
3. Results
3.1. CT Dataset

Swin-Unet achieves the best performance with segmentation accuracy.
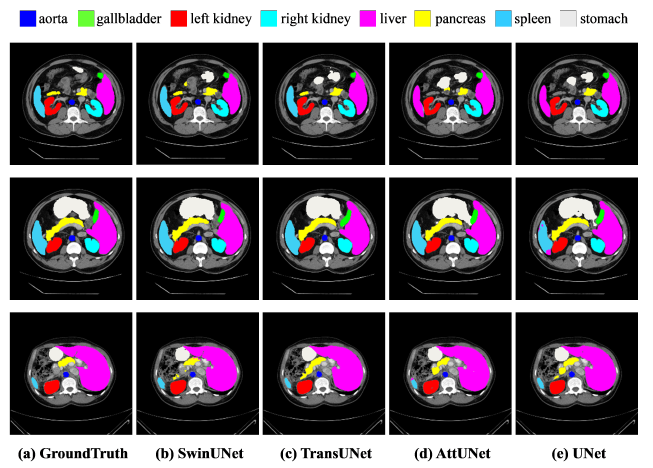
- CNN-based methods tend to have over-segmentation problems.
The pure Transformer approach without convolution can better learn both global and long-range semantic information interactions, resulting in better segmentation results.
3.2. MR Dataset
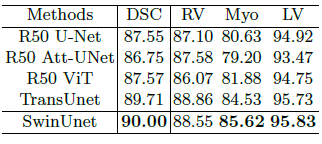
Swin-Unet is still able to achieve excellent performance with an accuracy of 90.00%, which shows that Swin-Unet has good generalization ability and robustness.
3.3. Ablation Study

- Bilinear interpolation, and transposed convolution are tried.
Swin-Unet combined with the patch expanding layer can obtain the better segmentation accuracy.

- The skip connections of our Swin-UNet are added in places of the 1/4, 1/8, and 1/16 resolution scales. The number of skip connections is changed to 0, 1, 2 and 3.
The segmentation performance of the model increases with the increase of the number of skip connections.

The input token sequence of Transformer will become larger, thus leading to improve the segmentation performance, but the computational load of the whole network has also increased significantly.

The increase of model scale hardly improves the performance of the model, but increases the computational cost of the whole network.
