Review — Attention Is All You Need (Transformer)
Using Transformer, Attention is Drawn, Long-Range Dependencies are Considered, Outperforms ByteNet, Deep-Att, GNMT, and ConvS2S

In this story, Attention Is All You Need, (Transformer), by Google Brain, Google Research, and University of Toronto, is reviewed. In this paper:
- A new simple network architecture, the Transformer, based solely on attention mechanisms, is proposed, which dispensing with recurrence and convolutions entirely.
This is a paper in 2017 NeurIPS with over 31000 citations. (Sik-Ho Tsang @ Medium) Transformer is a very famous deep learning architecture and technique since Transformer is later extended to modalities other than text, such as image, video and audio: NL: Non-Local Neural Networks, Image Transformer, SAGAN, Vision Transformer, ViT, Swin Transformer. Of course, it is popularly used in NLP: GPT, BERT.
Outline
- Transformer: Model Architecture
- Multi-Head Attention
- Applications of Attention in Transformer
- Position-wise Feed-Forward Networks
- Other Details
- Experimental Results
1. Transformer: Model Architecture

1.1. Framework
- Left: The encoder maps an input sequence of symbol representations (x1, …, xn) to a sequence of continuous representations z= (z1, …, zn).
- Right: Given z, the decoder then generates an output sequence (y1, …, ym) of symbols one element at a time. At each step the model is auto-regressive, consuming the previously generated symbols as additional input when generating the next.
The Transformer follows this overall architecture using stacked self-attention and point-wise, fully connected layers for both the encoder and decoder.
1.2. Encoder
The encoder is composed of a stack of N = 6 identical layers.
Each layer has two sub-layers. The first is a multi-head self-attention mechanism, and the second is a simple, position-wise fully connected feed-forward network.
- A residual connection is employed around each of the two sub-layers, followed by layer normalization.
- That is, the output of each sub-layer is LayerNorm(x + Sublayer(x)).
- All sub-layers in the model, as well as the embedding layers, produce outputs of dimension dmodel=512.
1.3. Decoder
The decoder is also composed of a stack of N = 6 identical layers.
In addition to the two sub-layers in each encoder layer, the decoder inserts a third sub-layer, which performs multi-head attention over the output of the encoder stack.
- Similar to the encoder, residual connections are employed around each of the sub-layers, followed by layer normalization.
- The self-attention sub-layer in the decoder stack is modified to prevent positions from attending to subsequent (future) positions. This masking, combined with fact that the output embeddings are offset by one position, ensures that the predictions for position i can depend only on the known outputs at positions less than i.
2. Multi-Head Attention

2.1. Scaled Dot-Product Attention

2.1.1. Procedures
The input consists of queries and keys of dimension dk, and values of dimension dv.
The dot products of the query with all keys are computed, each divided by √(dk), and a softmax function is applied to obtain the weights on the values.
- In practice, the attention function can be computed on a set of queries simultaneously, packed together into a matrix Q. The keys and values are also packed together into matrices K and V. The the matrix of outputs are:
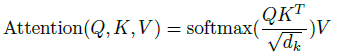
2.1.2. Reasons of Using Dot Product Attention over Additive Attention
- The two most commonly used attention functions are additive attention, and dot-product (multiplicative) attention.
- Additive attention computes the compatibility function using a feed-forward network with a single hidden layer.
While the two are similar in theoretical complexity, dot-product attention is much faster and more space-efficient in practice, since it can be implemented using highly optimized matrix multiplication code.
- While for small values of dk, the two mechanisms perform similarly.
- For large values of dk, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients. To counteract this effect, we scale the dot products by 1/√(dk).
2.2. Multi-Head Attention
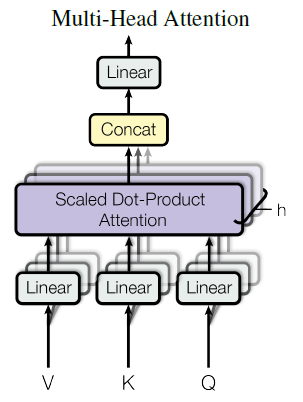
Instead of performing a single attention function with dmodel-dimensional keys, values and queries, It is found to be beneficial to linearly project the queries, keys and values h times with different, learned linear projections to dk, dk and dv dimensions, respectively.
- On each of these projected versions of queries, keys and values, the attention function is performed in parallel, yielding dv-dimensional output values. These are concatenated and once again projected:

- where the projections are parameter matrices WQi, WKi, WVi.
- In this model, h=8 parallel attention layers, or heads.
- For each of these, dk=dv=dmodel/h=64. Due to the reduced dimension of each head, the total computational cost is similar to that of single-head attention with full dimensionality.
3. Applications of Attention in Transformer

- Going back to the overall framework, the Transformer uses multi-head attention in three different ways (The 3 orange blocks):
- In “encoder-decoder attention” layers, the queries come from the previous decoder layer, and the memory keys and values come from the output of the encoder. This allows every position in the decoder to attend over all positions in the input sequence. This mimics the typical encoder-decoder attention mechanisms in sequence-to-sequence models.
- The encoder contains self-attention layers. In a self-attention layer all of the keys, values and queries come from the same place, in this case, the output of the previous layer in the encoder. Each position in the encoder can attend to all positions in the previous layer of the encoder.
- Similarly, self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position. To prevent leftward information flow in the decoder to preserve the auto-regressive property, the scaled dot-product attention is modified by masking out (setting to -∞) all values in the input of the softmax which correspond to illegal connections.
4. Position-wise Feed-Forward Networks

In addition to attention sub-layers, each of the layers in the encoder and decoder contains a fully connected feed-forward network, which consists of two linear transformations with a ReLU activation:
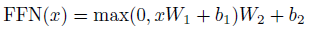
- Another way of describing this is as two convolutions with kernel size 1.
- The dimensionality of input and output is dmodel = 512, and the inner-layer has dimensionality dff = 2048, which is a bottleneck structure.
5. Other Details
5.1. Embeddings and Softmax
Learned embeddings are used to convert the input tokens and output tokens to vectors of dimension dmodel.
- The usual learned linear transformation and softmax function are used to convert the decoder output to predicted next-token probabilities.
- In Transformer, the same weight matrix is shared between the two embedding layers and the pre-softmax linear transformation.
- In the embedding layers, those weights are multiplied by √(dmodel).
5.2. Positional Encoding
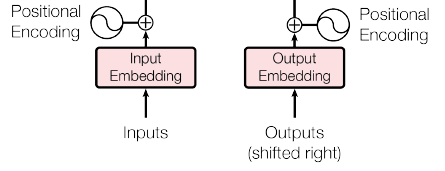
- Since Transformer contains no recurrence and no convolution, some information about the relative or absolute position of the tokens in the sequence are needed to inject.
- “Positional encodings” are added to the input embeddings at the bottoms of the encoder and decoder stacks. The positional encodings have the same dimension dmodel as the embeddings, so that the two can be summed.
sine and cosine functions of different frequencies are used:
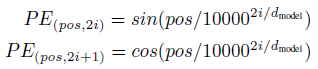
- where pos is the position and i is the dimension. Each dimension of the positional encoding corresponds to a sinusoid, it is hypothesis that it would allow the model to easily learn to attend by relative positions.
5.3. Why Attention

- There are 3 factors to motivate the use of self-attention:
- The total computational complexity per layer.
- The amount of computation that can be parallelized.
- The path length between long-range dependencies in the network.
- A self-attention layer connects all positions with a constant number of sequentially executed operations, whereas a recurrent layer requires O(n) sequential operations.
- In terms of computational complexity, self-attention layers are faster than recurrent layers when the sequence length n is smaller than the representation dimensionality d.
- A single convolutional layer with kernel width k<n does not connect all pairs of input and output positions. Doing so requires a stack of O(n=k) convolutional layers in the case of contiguous kernels, or O(logk(n)) in the case of dilated convolutions.
6. Experimental Results
6.1. Datasets
- WMT 2014 English-German dataset consists of about 4.5 million sentence pairs. Sentences were encoded using byte-pair encoding, which has a shared source-target vocabulary of about 37000 tokens.
- WMT 2014 English-French dataset consisting of 36M sentences and split tokens into a 32000 word-piece vocabulary. Each training batch contained a set of sentence pairs containing approximately 25000 source tokens and 25000 target tokens.
6.2. SOTA Comparison
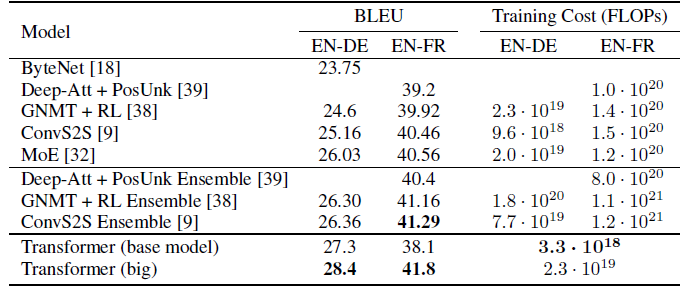
- Beam search with a beam size of 4 is used and length penalty α=0.6.
On the WMT 2014 English-to-German translation task, the big transformer model (Transformer (big)) outperforms the best previously reported models (including ensembles) by more than 2.0 BLEU, establishing a new state-of-the-art BLEU score of 28.4. Training took 3.5 days on 8 P100 GPUs.
Even the base model surpasses all previously published models and ensembles such as ByteNet, Deep-Att, GNMT, and ConvS2S.
- On the WMT 2014 English-to-French translation task, the proposed big model achieves a BLEU score of 41.0, outperforming all of the previously published single models, at less than 1/4 the training cost of the previous state-of-the-art model.
6.3. Model Variations

- (A): Single-head attention obtains 0.9 BLEU worse than the best setting, quality also drops off with too many heads.
- (B): Reducing the attention key size dk hurts model quality.
- (C) and (D): Bigger models are better, and dropout is very helpful in avoiding over-fitting.
- (E): The sinusoidal positional encoding is replaced with learned positional embeddings in [9], and nearly identical results to the base model is observed.
6.4. English Constituency Parsing
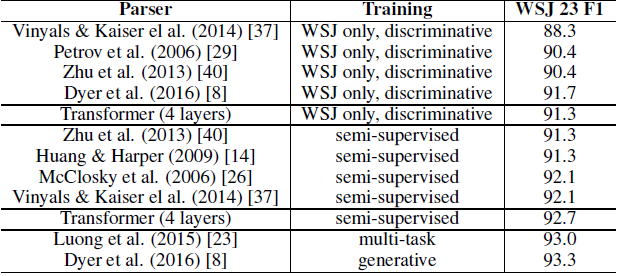
- In this task, the output is subject to strong structural constraints and is significantly longer than the input.
- A 4-layer transformer with dmodel=1024 is trained on the Wall Street Journal (WSJ) portion of the Penn Treebank [25], about 40K training sentences.
The Transformer generalizes well to English constituency parsing.
6.5. Attention Visualization
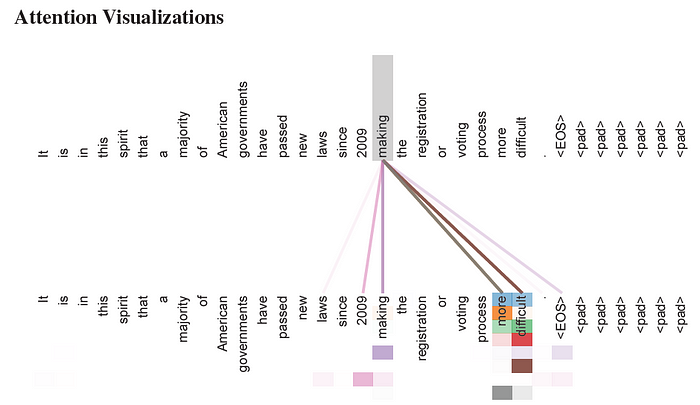
- Many of the attention heads attend to a distant dependency of the verb ‘making’, completing the phrase ‘making…more difficult’. Attentions here shown only for the word ‘making’. Different colors represent different heads.
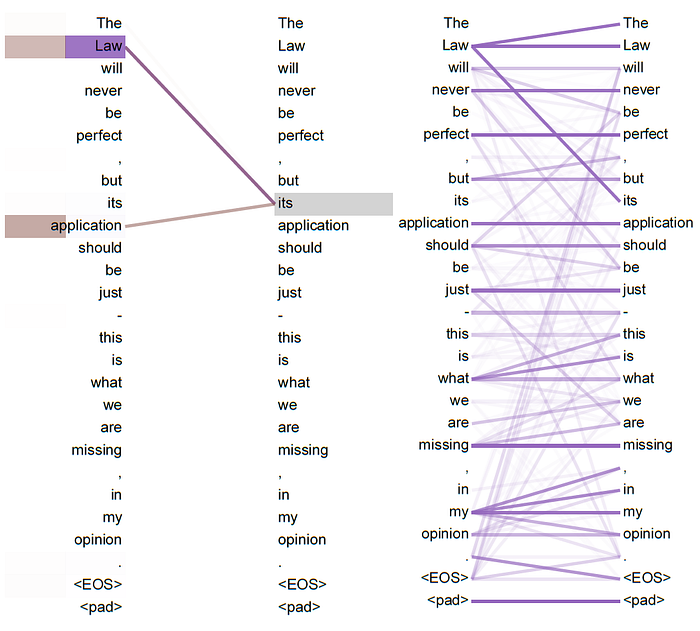
- Top: Full attentions for head 5.
- Bottom: Isolated attentions from just the word ‘its’ for attention heads 5 and 6.
I read the Transformer long time ago. But it is better for me to write about it after reading about the basics of language model and machine translation, as listed below (though there are already many blogs mentioning Transformer.)
Reference
[2017 NeurIPS] [Transformer]
Attention Is All You Need
Natural Language Processing (NLP)
Language Model: 2007 [Bengio TNN’07] 2013 [Word2Vec] [NCE] [Negative Sampling] 2014 [GRU] [Doc2Vec] 2015 [Skip-Thought] 2016 [GCNN/GLU]
Machine Translation: 2014 [Seq2Seq] [RNN Encoder-Decoder] 2015 [Attention Decoder/RNNSearch] 2016 [GNMT] [ByteNet] [Deep-ED & Deep-Att] 2017 [ConvS2S] [Transformer]
Image Captioning: 2015 [m-RNN] [R-CNN+BRNN] [Show and Tell/NIC] [Show, Attend and Tell]
