Review — UPSNet: A Unified Panoptic Segmentation Network
Panoptic Head, Combine Semantic & Instance Segmentation Heads
UPSNet: A Unified Panoptic Segmentation Network
UPSNet, by Uber ATG, University of Toronto, and The Chinese University of Hong Kong, 2019 CVPR, Over 200 Citations (Sik-Ho Tsang @ Medium)
Panoptic Segmentation, Semantic Segmentation, Instance Segmentation
- A unified panoptic segmentation network (UPSNet) is proposed for tackling the newly proposed panoptic segmentation task.
- On top of a single backbone residual network, there are a deformable convolution (DCNv1) based semantic segmentation head and a Mask R-CNN style instance segmentation head which solve these two subtasks simultaneously.
- More importantly, a parameter-free panoptic head is introduced, which leverages the logits from the previous two heads, to solve the panoptic segmentation via pixel-wise classification.
Outline
- Unified Panoptic Sementation Network (UPSnet)
- Experimental Results
1. Unified Panoptic Sementation Network (UPSnet)

- For panoptic segmentation, thing refers to the set of labels of instances (e.g. pedestrian, bicycle), whereas stuff refers to the rest of the labels that represent semantics without clear instance boundaries (e.g. street, sky).
- (Please feel free to read PS if interested.)
1.1. Backbone
- The backbone is the original Mask R-CNN backbone which exploits ResNet with FPN.
1.2. Instance Segmentation Head
- The instance segmentation head follows the Mask R-CNN design with a bounding box regression output, a classification output, and a segmentation mask output.
- The goal of the instance head is to produce instance aware representations that could identify thing classes better.
1.3. Semantic Segmentation Head

- The goal of the semantic segmentation head is to segment all semantic classes without discriminating instances.
- The semantic head consists of a deformable convolution, used in DCNv1, based subnetwork which takes the multi-scale feature from FPN.
- In particular, P2, P3, P4 and P5 feature maps of FPN are used, which contain 256 channels and are 1/4, 1/8, 1/16 and 1/32 of the original scale respectively.
- These feature maps first go through the same deformable convolution network independently and are subsequently upsampled to the 1/4 scale. We then concatenate them and apply 1×1 convolutions with softmax to predict the semantic class.
- RoI loss is used where the ground truth bounding box of the instance is used to crop the logits map after the 1×1 convolution and then resized to 28×28. This RoI loss is then the cross entropy computed over 28 × 28 patch which amounts to penalizing more on the pixels within instances.
1.4. Panoptic Segmentation Head

- The outputs (specifically per pixel logits) from instance head and semantic head are combined in the panoptic segmentation head.
- The logits from semantic head is denoted as X. X can then be divided along channel dimension into two tensors Xstuff and Xthing.
- The mask logits from instance head is denoted as Y.
- The parameter-free panoptic head is to generate the panoptic logits based on the logits of instance head and semantic head, as shown above.
- Logits for stuff are created based on XStuff.
- Logits for instances are based on logits from both instance head and semantic head.
- A novel mechanism is proposed to classify a pixel as the extra unknown class instead of making a wrong prediction.
- (The exact rules to generate panoptic logits are too lengthy if describing here. Please feel free to read the paper directly.)
2. Experimental Results
- RQ is the F1 score widely used for quality estimation in detection settings. SQ is the average IoU of matched segments.
- PQ is SQ multiplied by RQ: PQ=SQ×RQ.
- (For details of PQ, SQ, RQ metrics, please feel free to read PS.)
2.1. COCO
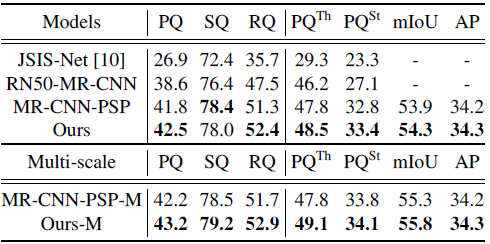
- Combined Method MR-CNN-PSP: uses a Mask R-CNN with a ResNet-50-FPN and a PSPNet with a ResNet-50 as the backbone and apply the combine heuristics to compute the panoptic segmentation.
UPSNet achieves better performance in all metrics except the SQ.
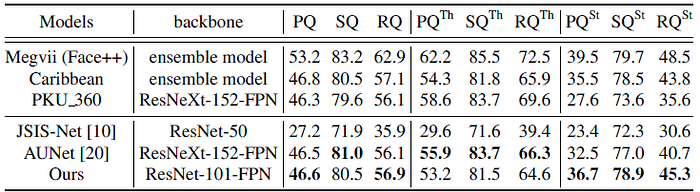
- Using ResNet-101 as the backbone, UPSNet achieves slightly better results compared to the recent AUNet [20] which uses ResNeXt-152.
UPSNet is on par with the second best model without using any special tricks.
In terms of the model size, RN50-MR-CNN, MR-CNN-PSP and UPSNet consists of 71.2M, 91.6Mand 46.1M parameters respectively. Therefore, UPSNet is significantly lighter.
2.2. Cityscapes
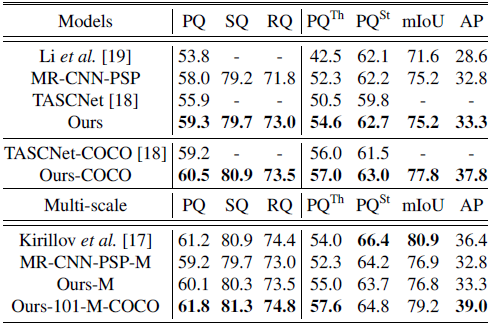
Under the same single scale testing, the proposed UPSNet achieves better performance than the combined method.
Although multi-scale testing significantly improves both the combined method and UPSNet, UPSNet is still slightly better.
2.3. Proposed Dataset
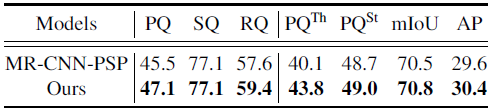
UPSNet performs significantly better than the combined method on all metrics except SQ.
2.4. Run Time
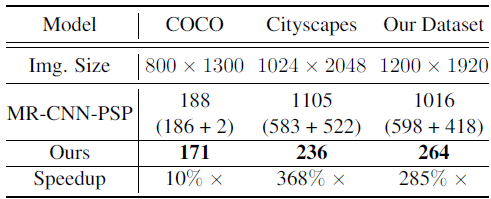
- GTX 1080 Ti GPU is used. All entries are averaged over 100 runs on the same image with single scale test.
The combined method takes about 3× time than UPSNet one.
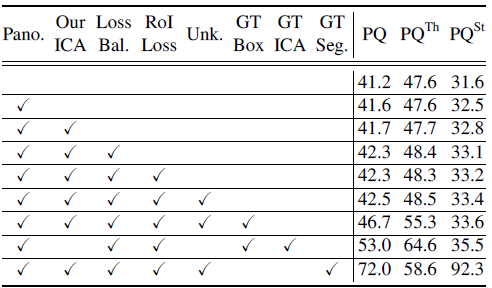
The most important part is the use of the GT semantic segmentation (GT Seg.) gives the largest gain of PQ, i.e., +29.5, which highlights the importance of improving semantic segmentation.

Reference
[2019 CVPR] [UPSNet]
UPSNet: A Unified Panoptic Segmentation Network
Panoptic Segmentation
2019 [PS] [UPSNet]
