Brief Review — A Large-Scale Multilingual Dataset for Speech Research
Multilingual LibriSpeech (MLS) Dataset
6 min readAug 8, 2024
A Large-Scale Multilingual Dataset for Speech Research
MTS Dataset, by Facebook AI Research
2020 arXiv v2, Over 400 Citations (Sik-Ho Tsang @ Medium)Acoustic Model / Automatic Speech Recognition (ASR) / Speech-to-Text (STT)
1991 … 2019 [SpecAugment] [Cnv Cxt Tsf] 2020 [FAIRSEQ S2T] [PANNs] [Conformer]
- A Multilingual LibriSpeech (MLS) dataset is proposed, which is derived from read audiobooks from LibriVox and consists of 8 languages, including about 44.5K hours of English and a total of about 6K hours for other languages.
- Additionally, Language Models (LM) and baseline Automatic Speech Recognition (ASR) models are provided.
Outline
- Multilingual LibriSpeech (MLS) Dataset
- Results
1. Multilingual LibriSpeech (MLS) Dataset
- Subsections (1.1) to (1.7): To have the Multilingual LibriSpeech (MLS) dataset, there are a lot of heursitics or data post processing to obtain the input data (audio), output labels (text), standardizing the input data and output labels.
- Subsection (1.8): Train/dev/test split.
- Section 2: Then, a model based on [20] is used for benchmarking.
For quick read: Subsection (1.1), (1.8) then Section 2.
1.1. Downloading Audiobooks

- The LibriVox audiobooks data available for each language measured using LibriVox APIs.
- English, German, Dutch, Spanish, French, Portuguese, Italian, Polish are selected for the MLS dataset preparation.
- All the audio data is downsampled from 48kHz to 16kHz.
1.2. Audio Segmentation

- Audio files downloaded from LibriVox have a huge variance in duration — from few minutes to hours. The audio files are to be segmented into 10–20 second segments.
- Acoustic models are trained in each of the languages using Time-Depth Separable (TDS) Convolutions [7] with Auto-Segmentation Criterion [8] (ASG) loss. For each language, models are trained on in-house datasets consisting of videos publicly shared by users. Only audio part of the videos is used and the data is completely de-identified.
- Audio egmentation has 2 steps:
- First, run inference on the audio and generate viterbi token sequence along with their timestamps. Since the audio files can be very long, wav2letter@anywhere framework [11] is used to perform the inference in a streaming fashion.
- Second, select the longest silence duration within 10 sec to 20 sec range from the start of an audio and split the audio at the mid point of the silence chunk to create a segment. If no silence frames are found between 10 sec to 20 sec from the starting point, we split the audio at 20 sec mark.
- This process guarantees that all the segments are between 10sec and 20sec. A minimum segment duration of 10 sec is kept so that the segments have sufficient number of words spoken which helps with better transcript retrieval.
1.3. Pseudo Label Generation
- Pseudo labels are generated for the segmented audio samples by performing a beam-search decoding with a 4-gram language model on the same acoustic models used for audio segmentation.
- For English, however, pre-trained model from [12] is used, which uses TDS encoder and CTC loss on LibriSpeech and pseudo labels from LibriVox .
1.4. Downloading Text Sources for Audiobook Data
- To generate the labels for the audio segments derived from audiobooks, the original textbook from which the speaker read the audiobook is needed. For English, 60K hours of audiobooks are read from four major website domains.
- For other languages, some manual approaches are used, e.g.: the text data is copied directly from the browser or extracted text from .pdf/.epub books, or HTML parsers are written to retrieve text data.
1.5. Text Normalization
- For normalizing the text, NFKC normalization is first performed and all the unwanted characters are removed, like punctuations, subscript/superscripts, emojis, escape symbols etc. The hyphens that used for “end-of-line hyphenation” and join the parts of words into a single word, are also removed.
- A list of valid unicode characters is prepared based on the language’s orthography and characters outside this range are filtered.
1.6. Transcript Retrieval
- The source text is first split into multiple overlapping documents of 1250 words each and striding by 1000 words. The documents are retrieved which best matches with the pseudo label for the audio segments using term-frequency inverse document-frequency (TF-IDF) similarity score on bigrams.
- A Smith-Waterman alignment [15] is then performed to find the best matching sub-sequence of words. A matching score of 2 is used and substitution, insertion, deletion score of -1 for the alignment algorithm.
After the above alignment procedure, a candidate target label is generated for each audio segment, which corresponds to the best match of the pseudo label in the source text of audiobook.
- WER > 40% are all filtered out.
1.7. Post Processing of Numbers, Hyphens, Apostrophe

- Figure 2: The matched text from the book is aligned with the pseudo label and the numbers in the matched text are replaced with the corresponding aligned words from the pseudo label.
- Figure 3: Heuristics are developed for hyphens and apostrophe.
1.8. Train/Dev/Test Split
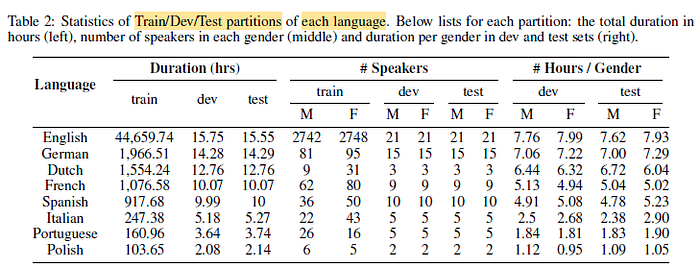
- No speaker overlap between the training, development and test set.
- Speakers are balanced in gender and duration in development and test sets. Gender classifier is used.
- There are sufficient audio hours and speakers assigned into development and test sets, to validate ASR model performance. Speakers with duration shorter than a threshold are assigned into the training set.
- The statistics for each language is shown above.
2. Results


- The encoder of AMs [20] is composed of a convolutional frontend followed by 36 4-heads Transformer blocks. The self-attention dimension is 768 and the feed-forward network (FFN) dimension is 3072 in each Transformer block. The output of the encoder is followed by a linear layer to the output classes.
- The AMs take 80-channel log-mel filterbanks as input and are trained end-to-end with Connectionist Temporal Classification (CTC) loss.
- To further improve the WER, beam-search decoding in wav2letter++ without using a LM (ZeroLM) and 5-gram language model are used.
WER improves when decoding with a 5-gram LM for all the languages except Polish due to Polish OOV rate of 13%.
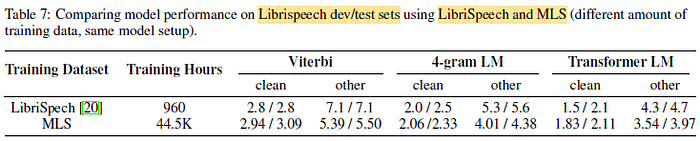
- Using the proposed MLS dataset for English and thereby using large amount of supervised training data improves the performance on LibriSpeech dev and test sets.
