Brief Review — A Lightweight 1-D Convolution Neural Network Model for Multi-class Classification of Heart Sounds
DWT + 1D-CNN for 5-Class Classification

A Lightweight 1-D Convolution Neural Network Model for Multi-class Classification of Heart Sounds
DWT + 1D-CNN, by National Institute of Technology Rourkela, Central University of Rajasthan
2022 ICETCI (Sik-Ho Tsang @ Medium)Heart Sound Classification
2013 … 2022 [CirCor Dataset] [CNN-LSTM] [DsaNet] [Modified Xception] [Improved MFCC+Modified ResNet] [Learnable Features + VGGNet/EfficientNet] [DWT + SVM] [MFCC+LSTM] 2023 [2LSTM+3FC, 3CONV+2FC] [NRC-Net]
==== My Other Paper Readings Are Also Over Here ====
- 1D-CNN model is trained on the multi-resolution domain features obtained using the discrete wavelet transform (DWT) for 5-category heart sound classification.
Outline
- Preprocessing & DWT
- 1D-CNN
- Results
1. Preprocessing & DWT
1.1. Preprocessing

- Re-sampling: Since the frequency range of the FHS and various pathological sound lie below 500 Hz [5], the signal is down-sampled from 8 kHz to 1 kHz.
- Normalization: The signal is amplitude normalized as below:

- Resizing: The length of the signal varies from 1.15 to 3.99 seconds. After the observation, it is found that each sample consists of approximately three cardiac cycles.
- The signal was resized to an equal length (2800 samples) after recognising the onset and offset of the signal.
- The above figure shows the normalized signal.
1.2. DWT

- DWT decomposes signal into low frequency and high frequency components. For high frequency component, it is downsampled and decomposed again into low frequency and high frequency components.
The heart sound signal is decomposed up to 5 levels using ‘coif5’ as mother wavelet.

- The obtained 5 detailed level coefficients and the approximation level signal is shown above.
They are arranged in 1D array which results in length of 2942. And it is fed into 1D-CNN.
2. 1D-CNN

The proposed CNN model is consist of 5 layers, 1 input layer, 2 convolution and pooling layers, 1 fully connected (FC) layer and 1 output layer (softmax).
- 50 epochs and 9 iterations in each epoch are used, resulting in 450 total iterations with a learning rate of 0.01. Batch size of 64 is used.
3. Results
3.1. Yaseen GitHub Dataset
- Yaseen GitHub Dataset is used, which has 1000 samples, 200 samples each for 5 categories, including the aortic stenosis (AS), mitral regurgitation (MR), mitral stenosis (MS), mitral valve prolapse (MVP), and normal (N).
- The sampling frequency of each sample is set to 1 kHz and a constant length of 2800 samples.
- The complete dataset was randomly split into train (70%) and test (30%) datasets.
3.2. Confusion Matrix
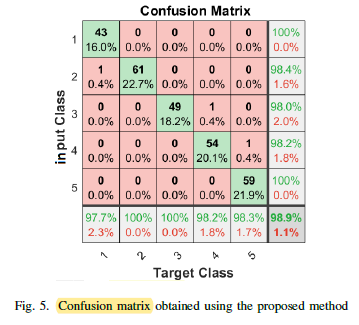
The proposed model efficiently classifies all the categories.
3.3. Per-Class Performance Evaluation

All 5 classes are classified with an F-score of above 98.18%. For the classes MR and N, the F-score is more than 99%.
- All 4 metrics are higher than 98% except the precision of As class which is 97.73%. It can also be observed that for all 5 categories, a high sensitivity (>98%) with high specificity(>99%) have been achieved.
3.4. SOTA Comparison
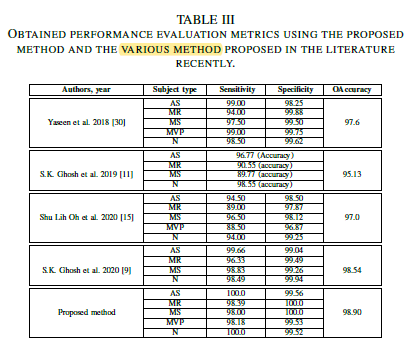
The highest accuracy (98.9%) is achieved using the proposed method.
