Brief Review — Classification of Heart Sound Signal Using Multiple Features
Open Access GitHub Dataset, MFCC+DWT as Features, SVM and DNN as Classifiers
Classification of Heart Sound Signal Using Multiple Features
Yaseen GitHub Dataset, by Sejong University
2018 MDPI J. Appl. Sci., Over 210 CitationsHeart Sound Classification
2013 [PASCAL] 2018 [RNN Variants] 2023 [2LSTM+3FC, 3CONV+2FC] [NRC-Net]
==== My Other Paper Readings Are Also Over Here ====
- Mel Frequency Cepstral Coefficient (MFCCs) and Discrete Wavelets Transform (DWT) features from the heart sound signal are used, and
- For learning and classification, support vector machine (SVM), deep neural network (DNN) and centroid displacement based k nearest neighbor are used to find the best one.
- The dataset is open to public as Yaseen GitHub Dataset.
Outline
- Normal and Abnomral Heart Sounds
- Feature Extraction and Learning
- Results
1. Normal and Abnomral Heart Sounds
- (Please skip this section if you know well.)

1.1. Heart Sound Preliminiaries
- The human heart is comprised of four chambers. Two of them are called atrias and they make the upper portion of the heart while remaining two chambers are called ventricles and they make lower portion of heart, and blood enters the heart through atrias and exit through ventricles.
Normal (Figure 1(a)): Normal heart sounds signal) are generated by closing and opening of the valves. of heart. The heart sound signals produced, are directly related to opening and closing of the valves, blood flow and viscosity.
- The movements of heart valves generate audible sounds of frequency range lower than 2 kHz, commonly refer to as “lub-dub”.
- The “lub” is the first portion in the heart sound signal and is denoted by (S1), it is generated from the closing of mitral and tricuspid valve. One complete cardiac cycle is the heart sound signal wave which starts from S1 and ends to the start of next S1 and it is described as one heartbeat.
- Closing of mitral valves is followed by closing of tricuspid valve and usually the delay between this operation is 20 to 30 ms. If the duration between these two sound components is in between 100 to 200 ms, it is called a split and its frequency range lies from 40 to 200 Hz and it is considered fatal if the delay is above 30 ms.
- “Dub”, is generated (the second heart sound component denoted by “S2”), when the aortic vales and pulmonary valves are closed. S1 is usually of longer time period and lower frequency than S2 which has shorter duration but higher frequency ranges (50 to 250 Hz).
- In each complete cycle of heart sound signal there are S1–S4 intervals, S3 and S4 are rare heart sounds and are not normally audible but can be shown on the graphical recording i.e., phonocardiogram [4].
1.2. Murmurs
- Beside “lub-dub”, some noisy signals may be present in the heart sounds called murmurs. Murmurs are classified as continuous murmurs, systolic murmurs and diastolic murmurs.
- Systolic murmurs are present during systole and they are generated during the ventricles contraction (ventricular ejection). In the heart sound component they are present between S1 and S2 hence are called as systolic murmurs.
Based on their types, these systolic murmurs can be called as either ejection murmurs (atrial septal defect, pulmonary stenosis, or aortic stenosis, (AS)) Figure 1e, or regurgitant murmurs (ventricular septal defect, tricuspid regurgitation, mitral regurgitation (MR) or mitral valve prolapse) Figure 1c.
- Diastolic murmurs are created during diastole (after systole), when the ventricles relax, which are present between the second and first heart sound portion, this type of murmur is usually due to mitral stenosis (MS) or aortic regurgitation (AR) by as shown in Figure 1d.
- Mitral valve prolapse (MVP) (Figure 1b): is a disease where the murmur sound is present in between the systole section.
- Figure 1f also shows the spectrum of a PCG.
2. Feature Extraction and Learning
2.1. Overall Workflow

- Two different types of features: MFCCs and DWT.
- To classify these features authors used SVM, centroid displacement based KNN and DNN as classifiers.
2.2. MFCC and DWT Features
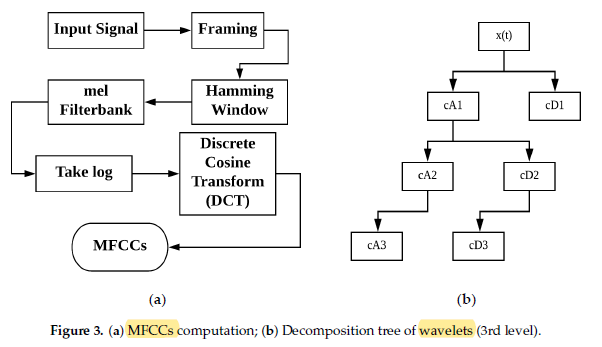
- 3 types of features are tried: MFCCs, DWT and MFCCs + DWT (fused features).
- (Please read the paper for more details about the features.)
2.3. SVM
- SVM is a hyperplane classifier.
2.3. DNN
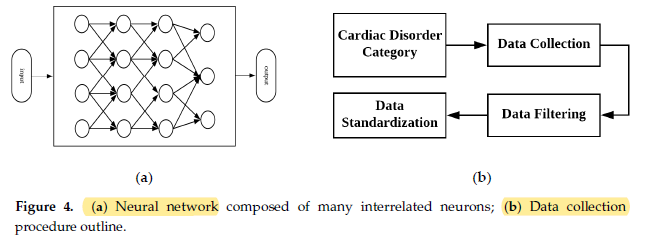
- The DNN model has 3 hidden layers and is trained for 2000 epochs.
- (But it is unclear there are how many neurons for each hidden layer and what activation function is used for each layer.)
- 5-fold cross validation is used for SVM and DNN.
3. Results
3.1. Proposed Yaseen GitHub Dataset

- The total numbers of audio files were 1000 for normal and abnormal categories (200 audio files/per category), the files are in .wav format.
3.2. Different Combinations of Features and Classifiers


There are clear improvements using SVM and DNN. But DNN couldn’t perform well compared to SVM due to limited amount of data.
The highest accuracy achieved is from fused MFCC and DWT features.

- Accuracy, F1 Score, Sensitivity and Specificity are also measured.
