Brief Review — A Snoring Sound Dataset for Body Position Recognition: Collection, Annotation, and Analysis
SSBPR Snore Sound Dataset
A Snoring Sound Dataset for Body Position Recognition: Collection, Annotation, and Analysis
SSBPR, by Wuhan University, and Zhongnan Hospital of Wuhan University
2023 InterSpeech (Sik-Ho Tsang @ Medium)Snore Sound Classification
2017 [INTERSPEECH 2017 Challenges: Addressee, Cold & Snoring] 2018 [MPSSC] [AlexNet & VGG-19 for Snore Sound Classification] 2019 [CNN for Snore] 2020 [Snore-GAN] 2021 [ZCR + MFCC + PCA + SVM] [DWT + LDOP + RFINCA + kNN]
==== My Healthcare and Medical Related Paper Readings ====
==== My Other Paper Readings Are Also Over Here ====
- Obstructive Sleep Apnea-Hypopnea Syndrome (OSAHS) is a chronic breathing disorder caused by a blockage in the upper airways. Yet, the classification of the obstruction site remains challenging in real-world clinical settings due to the influence of sleep body position on upper airways.
- In this paper, a snore-based sleep body position recognition dataset (SSBPR) consisting of 7570 snoring recordings, which comprises six distinct labels for sleep body position: supine, supine but left lateral head, supine but right lateral head, left-side lying, right-side lying and prone.
- Audio Spectrogram Transformer (AST) is used for benchmarking.
Outline
- Snore-based Sleep Body Position Recognition (SSBPR) Dataset
- Benchmarking Results
1. Snore-based Sleep Body Position Recognition (SSBPR) Dataset
1.1. Motivations
- The gold standard approach for diagnosing OSAHS is attended overnight polysomnography (PSG) in a sleep laboratory [3, 4].
- The standard diagnostic approach to determine the obstructive site is through the Drug-Induced Sleep Endoscopy (DISE) procedure.
- However, this method of diagnosis is associated with several limitations, such as extended examination time and elevated costs.
- Snoring is one of the most prominent symptoms of OSAHS and can be used to identify the obstructive site.
- However, sleep body position could influence the site, direction, and severity of upper airway obstruction in patients with OSAHS [12, 13]. In the natural sleep environment, people change their sleeping position several times nightly, affecting the corresponding snoring sounds generated and their excitation location in the upper airway.
Therefore, a novel snore-based sleep body position recognition dataset (SSBPR) is presented, and the snoring sounds of SSBPR dataset are annotated based on simultaneous PSG signals.
1.2. Data Collection

Data were collected from 20 adult patients who underwent overnight PSG at a local Sleep Medicine Research Center within the hospital.
- The snoring audio recording was obtained using a subminiature lavalier microphone, with a sampling frequency of 32 kHz and a sampling resolution of 16 bits (bit depth).
- The microphone was positioned on the patient’s face, facing the mouth, with an approximate distance of 3 cm, as shown in Figure 1 above, so that:
- Precise and detailed information about the sound is captured.
- Subtle nuances in the snoring sounds, such as variations in volume and pitch, can be captured which may not be evident when recording at greater distances.
- Background noise, like traffic or other sounds in the house, can be reduced.
1.3. Data Annotation
- A standard full PSG simultaneously records more than 10 physiologic signals during sleep, including electroencephalogram (EEG), electrooculogram (EOG), electromyogram (EMG), body position, video recording and et al.
- Sleep stages were scored by three experienced experts.
- Compumedics Profusion Sleeps software was used to record the data, display multiple channel recordings, manually score the data, report and export the recorded data.
In half of OSAHS patients, disease severity depends on trunk position and head position, in which the supine head and trunk position is usually the worst sleeping position [21, 22]. In positional OSAHS patients, lateral head rotation alone significantly differed at all levels.
- The annotation of snoring data (duration of 0.29–8.39 s) requires synchronized PSG signals: sleep stages, body position and video.
- The human sleep stages include wake, non-rapid eye movement (NREM) and rapid eye movement (REM) sleep, where NREM sleep encompasses three sleep stages, referred to as stage 1 (N1), stage 2 (N2), and stage 3 (N3).
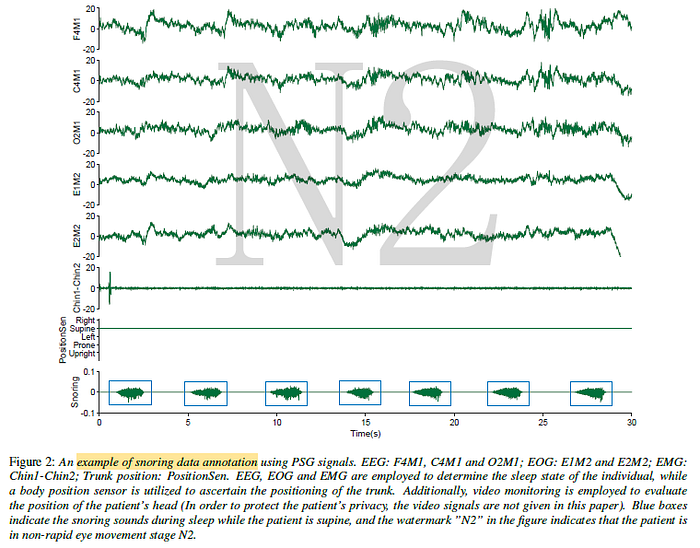
- “N2” indicates that the patient is in non-rapid eye movement stage N2 by EEG, EOG and EMG, which is used to determine whether the patient is asleep.
- The position and video signal together to identify the trunk and head position of the patient when snoring.
The snoring sounds in the SSBPR dataset finally are labeled with 6 types: supine, supine but left lateral head, supine but right lateral head, left-side lying, right-side lying and prone.
1.4. Data Statistics
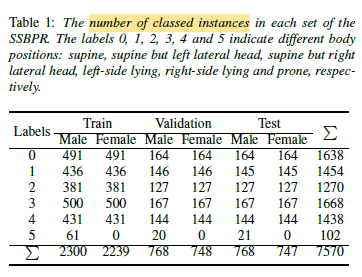
- OSAHS is more prevalent among men compared to women [24].
- Consistent with this notion, the sample population comprises 20 individuals aged 26 to 57 years, with a mean age of 43.1.
The SSBPR dataset contains a total of 7570 snoring samples.
Both genders had equal snoring sound samples except for prone labeling because female patients did not appear prone during PSG monitoring.
2. Benchmarking Results

- Audio Spectrogram Transformer (AST) is used.
- AST partitions the 2D snoring sound spectrogram into a sequence of 16 × 16 patches with overlapping areas. Each patch is then linearly transformed into a sequence of 1-D patch embeddings, augmented with learnable positional embeddings. The resulting sequence is then prepended with a classification token before input into a Transformer.
- The classification token output is obtained by applying a linear layer to the output embedding, which is used for the final classification task.
- Log Mel spectrograms are extracted, with a frequency dimension of 128, using a 25 ms Hamming window and a hop length of 10 ms. This gives us a resultant input size of 128 × 100t for t seconds of audio.
- The model has been trained on two NVIDIA GeForce RTX 3090 GPUs with batch size 12 for 30 epochs.
- Frequency/time masking data augmentation (SpecAugment) is used, with max time mask length of 48 frames and max frequency mask length of 48 bins.
- Binary cross-entropy loss is used.
As shown in Table 2, the model achieves an accuracy of 82.7%, 94.6% and 85.8% on male, female subjects and all subjects, respectively.
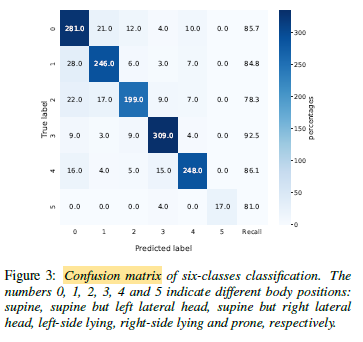
Figure 3 reveals significant differences between the classes of supine but right lateral head and left-side lying, with a range of 14.2% in the recall. This disparity may be attributed to data imbalance and limitations in the selected model architecture or model input.
