Review — AST: Audio Spectrogram Transformer
Modify Vision Transformer (ViT or DeiT) for Sound Classification or Audio Tagging

AST: Audio Spectrogram Transformer
AST, by MIT Computer Science and Artificial Intelligence Laboratory
2021 InterSpeech, Over 420 Citations (Sik-Ho Tsang @ Medium)Sound Classification / Audio Tagging
2015 [ESC-50, ESC-10, ESC-US]
==== My Other Paper Readings Are Also Over Here ====
- Audio Spectrogram Transformer (AST) is proposed, which is the first convolution-free, purely attention-based model.
- The aim of AST is to learn a direct mapping from audio spectrograms to corresponding labels, achieves new state-of-the-art results of 0.485 mAP on AudioSet, 95.6% accuracy on ESC-50, and 98.1% accuracy on Speech Commands V2.
Outline
- Audio Spectrogram Transformer (AST) Overall Architrecture
- Some AST Important Details & Modifications
- Results
1. Audio Spectrogram Transformer (AST) Overall Architrecture

1.1. Input & Preprocessing
First, the input audio waveform of t seconds is converted into a sequence of 128-dimensional log Mel filterbank (fbank) features computed with a 25ms Hamming window every 10ms. This results in a 128×100t spectrogram as input to the AST.
The spectrogram is then split into a sequence of N 16×16 patches with an overlap of 6 in both time and frequency dimension, where N = 12⌈(100t — 16)/10⌉ is the number of patches and the effective input sequence length for the Transformer.
1.2. Model Architecture
- Similar to ViT, each 16×16 patch is flatten to a 1D patch embedding of size 768 using a linear projection layer.
- A trainable positional embedding (also of size 768) is added to each patch embedding to allow the model to capture the spatial structure of the 2D audio spectrogram.
- A [CLS] classification token is appended at the beginning of the sequence.
In this paper, off-the-shelf image-based Transformer model, i.e. ViT or DeiT, is used, which is mentioned later.
1.3. Output
- The Transformer encoder’s output of [CLS] token serves as the audio spectrogram representation.
A linear layer with sigmoid activation maps the audio spectrogram representation to labels for classification. Binary cross-entropy loss is used.
2. Some AST Important Details & Modifications
- (However, directly using the model above and trained from scratch is difficult to obtain good results. There are a lot of details and modifications to adapt to audio datasets.)
2.1. ImageNet Pretraining
- Audio datasets typically do not have such large amounts of data to train AST.
ImageNet pretraining is needed. In practice, ImageNet pretrained weights are loaded to the model.
2.2. Input Channels & Normalization
- The input of ViT is a 3-channel image while the input of AST is a single-channel spectrogram.
The weights corresponding to each of the three input channels of the ViT patch embedding layer are averaged and use them as the weights of the AST patch embedding layer. This is equivalent to expanding a single-channel spectrogram.
The input audio spectrogram is normalized so that the dataset mean and standard deviation are 0 and 0.5, respectively.
2.3. Positional Embedding Adaptation
- The input shape of ViT is fixed (either 224×224 or 384×384) while the length of an audio spectrogram can be variable.
A cut and bi-linear interpolate method is proposed for positional embedding adaptation.
- For example, for a ViT that takes 384×384 image input and uses a patch size of 16×16, the number of patches and corresponding positional embedding is (384/16)×(384/16) = 24×24 = 576.
If an AST that takes 10-second audio input has 12×100 patches, the first dimension 24 in ViT is cut down to 12 in AST. The second dimension 24 in ViT is interpolated to 100 in AST.
- Authors directly reuse the positional embedding for [CLS] token only.
2.4. Output
- The last classification layer of the ViT is discarded.
A new one is reintialized for AST.
2.5. Model
In practice, pretrained data-efficient image Transformer (DeiT), a ViT variant, is used.
DeiT has two [CLS] tokens; they are averaged as a single [CLS] token for audio training.
2.6. Training Strategy
Balanced sampling (for full set experiments only), data augmentation (including mixup [28] with mixup ratio=0.5 and spectrogram masking [29] with max time mask length of 192 frames and max frequency mask length of 48 bins), and model aggregation (including weight averaging [30] and ensemble [31]).
- For weight averaging, all weights of the model checkpoints from the first to the last epoch are averaged.
- For ensemble, there are two settings: 1) Ensemble-S: The experiment is run three times with the exact same setting, but with a different random seed, then the output of the last checkpoint model of each run is averaged. 2) Ensemble-M: models trained with different settings are ensembled, specifically, the three models are ensembled in Ensemble-S together with another three models trained with different patch split strategies.
- (Although I have mentioned many details seems, there are still a lot that not yet mentioned. Please feel free to read the paper directly.)
3. Results
3.1. AudioSet

The proposed AST outperforms the previous best system in [8] in all settings.
For the balanced AudioSet (about 1% of the full set), AST can work better than CNN-attention hybrid models even when the training set is relatively small.
3.2. Ablation Study
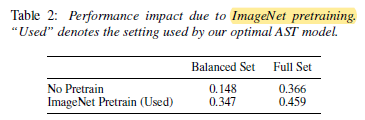
- ImageNet pretraining can greatly reduce the demand for in-domain audio data for AST.
ImageNet pretrained AST noticeably outperforms randomly initialized AST for both balanced and full AudioSet experiments.
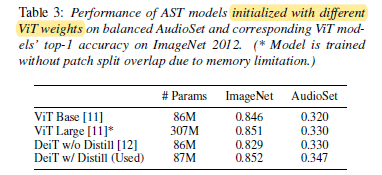
AST using the weights of the DeiT model with distillation that performs best on ImageNet 2012 also performs best on AudioSet.
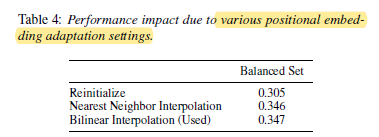
The cut and bi-linear interpolate method performs better than a fully randomly reinitialized model.
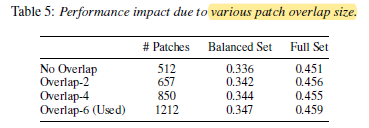
The performance improves with the overlap size for both balanced and full set experiments. Even with no patch split overlap, AST can still outperform the previous best system in [8].
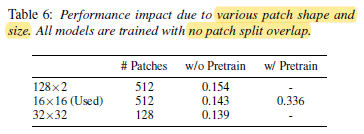
- Using 128×2 rectangle patches leads to better performance than using 16×16 square patches when both models are trained from scratch.
However, considering there is no 128×2 patch based ImageNet pretrained models, using 16×16 patches is still the current optimal solution.
3.3. ESC-50 & Speech Commands V2
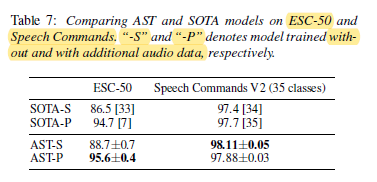
On ESC-50, AST-S (Ensemble-S) achieves 88.7±0.7 and AST-P (Ensemble-P) achieves 95.6±0.4, both outperform SOTA models in the same setting.
On Speech Commands V2, AST-S model achieves 98.11±0.05, outperforms the SOTA model in [9].
