Brief Review — CheXternal: Generalization of Deep Learning Models for Chest X-ray Interpretation to Photos of Chest X-rays and External Clinical Settings
CheXternal, Investigates Clinically Relevant Distribution Shifts Issue
CheXternal: Generalization of Deep Learning Models for Chest X-ray Interpretation to Photos of Chest X-rays and External Clinical Settings
CheXternal, by Stanford University
2021 CHIL (Sik-Ho Tsang @ Medium)
Medical Imaging, Medical Image Classification, Image Classification
- It is found that there is poor generalization due to data distribution shifts in clinical settings is a key barrier to implementation.
- 8 different chest X-ray models when applied to (1) smartphone photos of chest X-rays and (2) external datasets without any finetuning.
- This is a paper from the research group of Andrew Ng.
Outline
- CheXternal Setup
- Results
1. CheXternal Setup

- The diagnostic performance is studied for 8 different chest X-ray models when applied to (1) smartphone photos of chest X-rays and (2) external set (NIH) without any finetuning.
2. Results
2.1. Smartphone Photo of Chest X-Rays


- On photos of chest X-rays, all 8 models experienced a statistically significant drop in task performance.

- However, only 3 performed significantly worse than radiologists on average.
2.2. External Set (CheXpert Hidden Test Set & NIH)

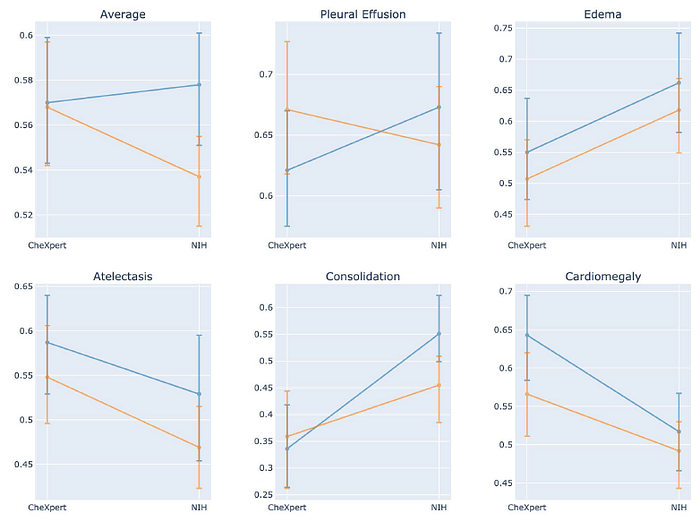

- On the external set, none of the models performed statistically significantly worse than radiologists, and five models performed statistically significantly better than radiologists.
The results demonstrate that some chest X-ray models, under clinically relevant distribution shifts, were comparable to radiologists while other models were not.
One of the topics that Prof. Andrew Ng focuses is the data-centric issue in AI. Here, by collaborating with radiologists, the data-centric issue is studied in the field of medical X-ray imaging.
Reference
[2021 CHIL] [CheXternal]
CheXternal: Generalization of Deep Learning Models for Chest X-ray Interpretation to Photos of Chest X-rays and External Clinical Settings
1.8. Biomedical Image Classification
2017 [ChestX-ray8] 2019 [CheXpert] [Rubik’s Cube] 2020 [VGGNet for COVID-19] [Dermatology] [ConVIRT] [Rubik’s Cube+] 2021 [MICLe] [MoCo-CXR] [CheXternal]
