Brief Review — Contrastive Learning of Medical Visual Representations from Paired Images and Text
ConVIRT, Image+Text Contrastive Learning, Outperforms Image-Based Contrastive Learning SimCLR & MoCo v2

Contrastive Learning of Medical Visual Representations from Paired Images and Text, ConVIRT, by Stanford University,
2020 arXiv v1, Over 100 Citations (Sik-Ho Tsang @ Medium)
Self-Supervised Learning, Contrastive Learning, Medical Image Classification, Image Retrieval
- Contrastive VIsual Representation Learning from Text (ConVIRT), is proposed, which pretrains medical image encoders with the paired image and text data via a bidirectional contrastive objective between the two modalities.
Outline
- Contrastive VIsual Representation Learning from Text (ConVIRT)
- Results
1. Contrastive VIsual Representation Learning from Text (ConVIRT)

1.1. Overall Framework
- At a high level, each input image xv and text xu are converted into d-dimensional vector representations v and u respectively, following a similar processing pipeline.
- For each input image xv, our method starts by drawing a random view ~xv from xv with a sampled transformation function tv~T, where T represents a family of stochastic image transformation functions described later.
- Next, the encoder function fv transforms ~xv into a fixed-dimensional vector hv, followed by a non-linear projection function gv which further transforms hv into vector v:

- Similar for text input:

1.2. Contrastive Loss
- An image-to-text contrastive loss for the i-th pair:

- where <> is the cosine similarity function.
- This loss takes the same form as the InfoNCE loss in CPCv1 that maximally preserve the mutual information between the true pairs under the representation functions.
- A similar text-to-image contrastive loss is:

- The overall contrastive loss is:

1.3. Realization
- gv and gu are modeled as single-hidden-layer neural networks:

- where σ is a ReLU non-linearity, and similarly for gu.
- For the image encoder fv, ResNet-50 is used.
- For the text encoder fu, BERT encoder followed by a max-pooling layer over all output vectors, is used.
- For the image transformation family tv~T, it is a five random transformations: cropping, horizontal flipping, affine transformation, color jittering and Gaussian blur.
- For the text transformation function tu, a simple uniform sampling of a sentence from the input document xu, is used, to preserve the semantic meaning.
2. Results
2.1. Medical Image Classification

- (a) Linear Classification: Compared to random initialization, ImageNet initialization provides markedly better representations.
- In-domain image initialization methods that use paired image-text data further improve over ImageNet initialization in almost all settings.
On three out of the four tasks, with only 1% training data ConVIRT is able to achieve classification results better than the default ImageNet initialization with 100% training data, highlighting the high quality of the learned representations from ConVIRT.
- (b) Fine-Tuning: ImageNet initialization is again better than random initialization with smaller margins.
- All in-domain initialization methods are better than the popular ImageNet initialization in most settings.
The proposed ConVIRT pretraining again achieves the best overall results in 10 out of the 11 settings, with the exception of the CheXpert dataset with all training data used, where the result of ConVIRT is similar to that of the Caption-Transformer result.
2.2. Image Retrieval
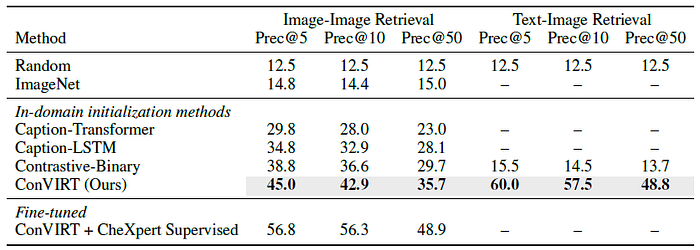
- Using ImageNet pretrained CNN weights in a zero-shot image retrieval setting is only better than random guess by small margins.
- All in-domain pretrained CNN weights achieve much better retrieval performance than ImageNet weights.
The proposed ConVIRT pretraining achieves the best overall retrieval results on all metrics.
2.3. Visualization

- ConVIRT pretraining achieves a better clustering of the images in the t-SNE plots. On the other hand, the lack of clear separations between groups suggests room for further improvement.
2.4. Compared with Image-Only Contrastive Learning
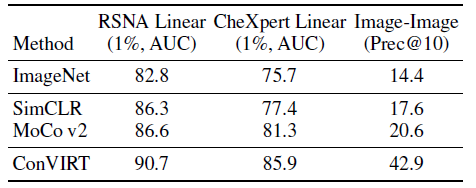
- Compared to ImageNet initialization, both contrastive methods SimCLR and MoCo v2 lead to marginal to moderate improvements on the classification and retrieval tasks.
However, ConVIRT training strategy substantially outperforms both SimCLR and MoCo v2 methods on all tasks.
According to OpenReview, ConVIRT is rejected in 2021 ICLR though it has got over 100 citations already.
Reference
[2020 arXiv] [ConVIRT]
Contrastive Learning of Medical Visual Representations from Paired Images and Text
Self-Supervised Learning
1993 … 2020 [CMC] [MoCo] [CPCv2] [PIRL] [SimCLR] [MoCo v2] [iGPT] [BoWNet] [BYOL] [SimCLRv2] [BYOL+GN+WS] [ConVIRT] 2021 [MoCo v3] [SimSiam] [DINO] [Exemplar-v1, Exemplar-v2] [MICLe] [Barlow Twins] [MoCo-CXR]
Biomedical Image Classification
2017 [ChestX-ray8] 2019 [CheXpert] 2020 [VGGNet for COVID-19] [Dermatology] [ConVIRT] 2021 [MICLe] [MoCo-CXR]
