Brief Review — COBERT: COVID-19 Question Answering System Using BERT
COBERT, Answers Generated by DistilBERT

COBERT: COVID-19 Question Answering System Using BERT
COBERT, by l-Balqa Applied University, Bharati Vidyapeeth’s College of Engineering, SRM Institute of Science and Technology, Chandigarh University
2021 Arab. J. Sci. Eng., Over 60 Citations (Sik-Ho Tsang @ Medium)Question Answering (QA)
2016 [SQuAD 1.0/1.1] 2017 [Dynamic Coattention Network (DCN)] 2018 [SQuAD 2.0]
My Healthcare and Medical Related Paper Readings
==== My Other Paper Readings Are Also Over Here ====
- COBERT is proposed, which is a retriever-reader dual algorithmic system that answers the complex queries by searching a document of 59K corona virus-related literature made accessible through the Coronavirus Open Research Dataset Challenge (CORD-19).
- The retriever is composed of a TF-IDF vectorizer capturing the top 500 documents with optimal scores.
- The reader which is pre-trained Bidirectional Encoder Representations from Transformers (BERT) on SQuAD 1.1 dev dataset.
Outline
- COBERT
- Results
1. COBERT
1.1. Open-Domain QA vs Closed Domain QA

- A closed-domain system deals with questions under an exact domain, i.e., medicine or automotive maintenance.
- It is largely different from open-domain QA.
1.2. COBERT Retriever

- Basically, it converts these documents into Tf-IDF vectorizer along with an input query and evaluates the cosine similarity of the document and input query.
- TF-IDF features are based on uni grams and bi-grams. TF-IDF Retriever segregated into two terms. TF (Term Frequency) and IDF (Inverse Document Frequency):



- Further, this schema calculates the cosine similarity in-between the question sentence and every document of the database:

- where:

- For the closed domain, the 59,000 articles from CORD-19 are included as the corpus. As the whole text of the paragraphs is used, the data is divided into chunks of 10,000 for pre-processing to avoid system crashes.
- The top articles identified based on a cosine similarity between the question string and the abstract text.
1.3. COBERT Reader
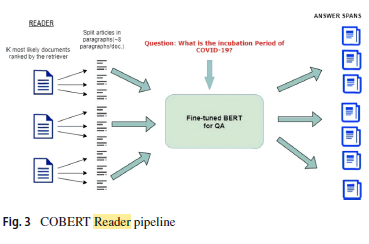
- The reader used themost likely document, which is ranked by the retriever. To answer the question, the reader splits the document into a paragraph.
DistilBERT pre-trained on SQuAD 1.1 is used. The model has 6 layers, 768 dimensions, and 12 heads, totalizing 66M parameters.
- The top 3 answers are selected based on a weighted score between the retriever score and reader score. Retriever score weight is set as 0.35.
2. Results
2.1. Qualitative Results

- The system outputs not only an answer but also the title of the document/article, the paragraph where the answer was found.
- Every query, model outputs 3 answers. For the sake of simplicity, only a single instance of the answer is presented to the query.
2.2. Quantitative Results

DistilBERT achieves 80.1% EM and 87.5% F1 while being much faster and lighter. Whereas, after fitting the pipeline on the CORD-19 corpus, the model achieves 81.6% EM and 87.3% F1-score.
