Review — DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Smaller DistilBERT by Distilling BERT

DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
DistilBERT, by Hugging Face
2019 NeurIPS Workshop, Over 1500 Citations (Sik-Ho Tsang @ Medium)
Language Model, Natural Language Processing, NLP, BERT
- NLP operating these large models in on-the-edge and/or under constrained computational training or inference budgets remains challenging.
- Knowledge distillation is leveraged during the pre-training phase, which reduces the size of a BERT model by 40%, while retaining 97% of its language understanding capabilities and being 60% faster.
Outline
- DistilBERT: Knowledge Distillation on BERT
- Experimental Results
1. DistilBERT: Knowledge Distillation on BERT
1.1. Distillation
- Knowledge distillation, used in Distillation, is a compression technique in which a compact model — the student — is trained to reproduce the behaviour of a larger model — the teacher — or an ensemble of models.
- The student is trained with a Distillation loss over the soft target probabilities of the teacher:

- where ti (resp. si) is a probability estimated by the teacher (resp. the student).
- A softmax-temperature is introduced:

- where T controls the smoothness of the output distribution and zi is the model score for the class i.
- The same temperature T is applied to the student and the teacher at training time, while at inference, T is set to 1 to recover a standard softmax.
- (Please feel free to read Distillation if interested.)
1.2. BERT Distillation
- The final training objective is a linear combination of the Distillation loss Lce with the supervised training loss, in this case the masked language modeling loss Lmlm.
- It is also found that it is beneficial to add a cosine embedding loss (Lcos) which will tend to align the directions of the student and teacher hidden states vectors.
1.3. DistilBERT Model
- The student — DistilBERT — has the same general architecture as BERT.
- The token-type embeddings and the pooler are removed while the number of layers is reduced by a factor of 2.
- It is found that variations on the hidden size dimension have a smaller impact on computation efficiency (for a fixed parameters budget) than variations on other factors like the number of layers. Thus, only the number of layers is reduced.
- The student is initialized from the teacher by taking one layer out of two.
1.4. Training
- DistilBERT is distilled on very large batches leveraging gradient accumulation (up to 4K examples per batch) using dynamic masking and without the next sentence prediction objective. (BERT uses next sentence prediction while RoBERTa finds that it hurts the performance.)
- DistilBERT is trained on the same corpus as the original BERT model: a concatenation of English Wikipedia and Toronto Book Corpus.
- DistilBERT is trained on 8 16GB V100 GPUs for approximately 90 hours. For the sake of comparison, the RoBERTa model required 1 day of training on 1024 32GB V100.
2. Experimental Results
2.1. GLUE

- Among the 9 tasks, DistilBERT is always on par or improving over the ELMo baseline (up to 19 points of accuracy on STS-B).
DistilBERT also compares surprisingly well to BERT, retaining 97% of the performance with 40% fewer parameters.
2.2. IMDb & SQuAD
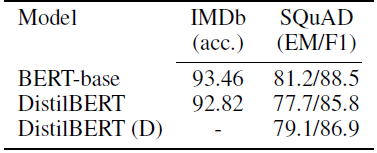
DistilBERT is only 0.6% point behind BERT in test accuracy on the IMDb benchmark while being 40% smaller.
On SQuAD, DistilBERT is within 3.9 points of the full BERT.
2.3. Size and Inference Speed
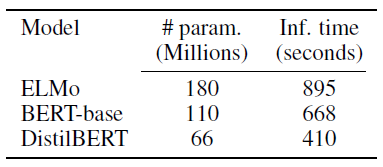
DistilBERT has 40% fewer parameters than BERT and is 60% faster than BERT.
- The average inference time is measured on a recent smartphone (iPhone 7 Plus) against the previously trained question answering model based on BERT-base.
Excluding the tokenization step, DistilBERT is 71% faster than BERT, and the whole model weighs 207 MB (which could be further reduced with quantization).
2.4. Ablation Study
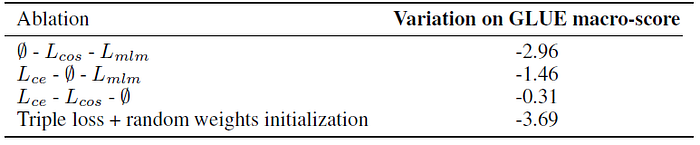
Removing the Masked Language Modeling loss has little impact while the two Distillation losses account for a large portion of the performance.
Reference
[2019 NeurIPS Workshop] [DistilBERT]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Natural Language Processing (NLP)
Language/Sequence Model: 2007 [Bengio TNN’07] 2013 [Word2Vec] [NCE] [Negative Sampling] 2014 [GloVe] [GRU] [Doc2Vec] 2015 [Skip-Thought] 2016 [GCNN/GLU] [context2vec] [Jozefowicz arXiv’16] [LSTM-Char-CNN] 2017 [TagLM] [CoVe] [MoE] 2018 [GLUE] [T-DMCA] [GPT] [ELMo] 2019 [T64] [Transformer-XL] [BERT] [RoBERTa] [GPT-2] [DistilBERT]
