Brief Review — Machine Listening for Heart Status Monitoring: Introducing and Benchmarking HSS — the Heart Sounds Shenzhen Corpus
HSS Dataset for Heart Sound Classification

Machine Listening for Heart Status Monitoring: Introducing and Benchmarking HSS — the Heart Sounds Shenzhen Corpus
HSS Dataset, by Shenzhen University General Hospital, The University of Tokyo, University of Augsburg, Carnegie Mellon University, Wenzhou Medical University, Imperial College London, and University of Augsburg,
2020 JBHI, Over 30 Citations (Sik-Ho Tsang @ Medium)5.7. Heart Sound Classification
2013 … 2021 [CardioXNet] 2022 [CirCor] [CNN-LSTM] [DsaNet] 2023 [2LSTM+3FC, 3CONV+2FC] [NRC-Net]
==== My Other Paper Readings Are Also Over Here ====
- Relevant databases and benchmark studies are scarce.
- In this paper, Heart Sounds Shenzhen Corpus (HSS) is introduced, which was first released during the recent INTERSPEECH 2018 COMPARE Heart Sound subchallenge.
Outline
- HSS Dataset
- Feature Extraction and Classification Models
- Benchmarking Results
1. HSS Dataset

Although PhysioNet has more instances, the data acquisition system, environment, and the annotation procedures are not consistent. This may results in obstacles and uncertainties for building an intelligent model.

- There were 170 subjects involved (female: 55, male:115) with various health conditions including coronary heart disease, heart failure, arrhythmia, hypertension, hyperthyroid, valvular heart disease and congenital heart disease amongst others.
- The ages of participants ranged from 21 to 88 years (65.4±13.2 years).
- Sampling rate: 4kHz.

- The data was acquired from 4 locations on the body (cf. Fig. 2), i. e., auscultatory mitral, aortic valve auscultation, pulmonary valve auscultation, and auscultatory areas of the tricuspid valve.
- For each area as mentioned previously, a duration of 30 seconds on average (ranging from 29.808 s to 30.152 s) in a sitting or supine position of the subjects was recorded, which resulted in 845 recordings within 422.82 min length from the 170 subjects.
The HSS has 3 category heart sounds to be classified: normal, mild, and moderate/severe.

The data is split into train, development (dev), and test sets, ending up with 502/180/163 instances for the train/development/test sets collected from 100/35/35 subjects.
2. Feature Extraction and Classification Models
2.1. Acoustic Features

- 65 basic acoustic features are used.
- These features are extracted by the open source toolkit OPENSMILE [49], [50], which was also used to train the baseline system in the INTERSPEECH 2018 COMPARE challenge Heart Sound sub-challenge [8].
2.2. Log Mel Features
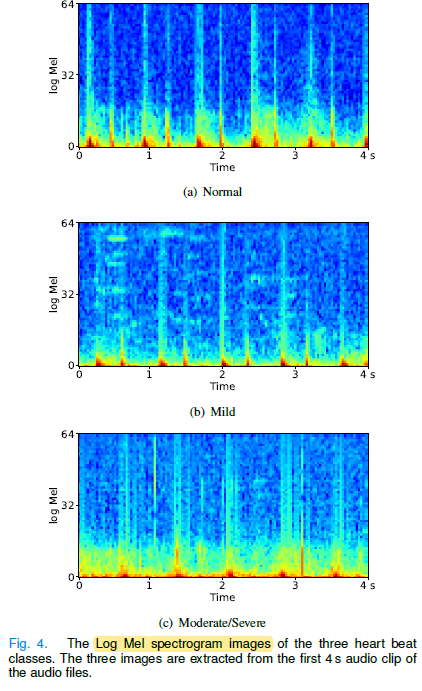
- Log Mel spectrograms of typical heart sounds are also extracted.
2.3. Classification Models
- SVM and RNN are investigated.
- In RNN, LSTM and GRU are investigated.
2.4. Fusion Strategy
- 2 main strategies are investigated.
- In the scenario of early fusion, features are concatenated directly before being fed into the machine learning model.
- Late fusion is implemented by independently training the models with different feature sets, and the final prediction will be made by using a voting method.
- 2 voting methods: the majority voting (MV), and the margin sampling voting (MSV). For MV, the final prediction will be given to the one which has been voted for most commonly by the individually trained classifiers. In the strategy of MSV, the final prediction will be set to the choice made by the ‘most confident’ individual classifier.
2.5. Metrics
- Unweighted average recall (UAR) is used:
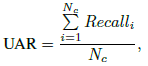
3. Benchmarking Results
3.1. Benchmarking

SVM (49.7% of UAR) shows a better performance than RNN, for both the LSTM RNN (43.3% of UAR) and the GRU RNN (42.3% of UAR).
When comparing the classifiers trained by the Log Mel feature set, SVM outperforms RNN (LSTM, or GRU).
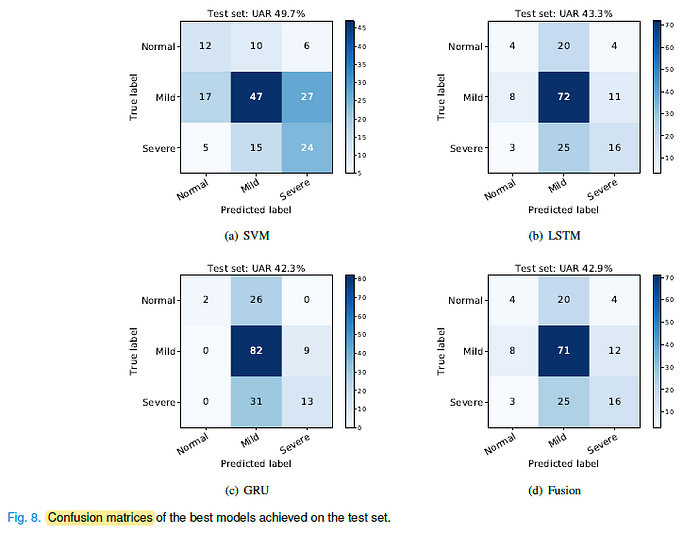
- RNN models (LSTM, or GRU) outperform the SVM model on the recall of ‘mild’ type of heart sounds.
- SVM model can achieve better recalls for both of the ‘normal’, and the ‘severe’ types of heart sounds.
The best result (42.9% of UAR) achieved on the test set still yields to the single SVM model (49.7% of UAR).
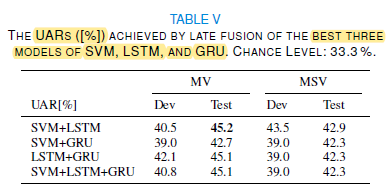
- The fused models cannot outperform the single models in this work.
3.2. SOTA Comparisons
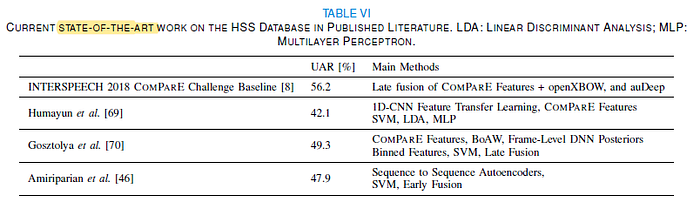
- Untill now (at that moment), the INTERSPEECH 2018 COMPARE challenge baseline keeps the highest UAR for the HSS. This record was achieved by a late fusion (MV) by two optimised models, i. e., a SVM trained by COMPARE LLDs processed by the bag-of-audio-words (BoAW) approach [71], and an SVM trained by representations learnt by deep sequence to sequence autoencoders (Seq2Seq) [72].
