Brief Review — Transfer Learning in Biomedical Natural Language Processing: An Evaluation of BERT and ELMo on Ten Benchmarking Datasets
BLUE Dataset for Biomedical NLP
4 min readDec 1, 2023

Transfer Learning in Biomedical Natural Language Processing: An Evaluation of BERT and ELMo on Ten Benchmarking Datasets
BLUE, by National Institutes of Health
2019 BioNLP, Over 760 Citations (Sik-Ho Tsang @ Medium)Medical/Clinical NLP/LLM
2017 … 2021 [MedGPT] [Med-BERT] [MedQA] [PubMedBERT] [MMLU] 2023 [Med-PaLM]
==== My Other Paper Readings Are Also Over Here ====
Outline
- Biomedical Language Understanding Evaluation (BLUE) Benchmark
- Benchmarking Models & Results
1. Biomedical Language Understanding Evaluation (BLUE) Benchmark

1.1. Sentence Similarity
- BIOSSES is a corpus of sentence pairs selected from the Biomedical Summarization Track Training Dataset in the biomedical domain. Five curators judged their similarity, using scores that ranged from 0 (no relation) to 4 (equivalent).
- MedSTS is a corpus of sentence pairs selected from Mayo Clinics clinical data warehouse. To develop MedSTS, two medical experts graded the sentence’s semantic similarity scores from 0 to 5.
1.2. Named Entity Recognition
- BC5CDR is a collection of 1,500 PubMed titles and abstracts selected from the CTD-Pfizer corpus and was used in the BioCreative V chemicaldisease relation task (Li et al., 2016).
- ShARe/CLEF eHealth Task 1 Corpus is a collection of 299 deidentified clinical free-text notes from the MIMIC II database (Suominen et al., 2013).
1.3. Relation Extraction
- DDI extraction 2013 corpus is a collection of 792 texts selected from the DrugBank database and other 233 Medline abstracts (Herrero-Zazo et al., 2013).
- ChemProt consists of 1,820 PubMed abstracts with chemical-protein interactions annotated by domain experts and was used in the BioCreative VI text mining chemical-protein interactions shared task (Krallinger et al., 2017).
- i2b2 2010 shared task collection consists of 170 documents for training and 256 documents for testing, which is the subset of the original dataset (Uzuner et al., 2011).
1.4. Document Multilabel Classification
- HoC (the Hallmarks of Cancers corpus) consists of 1,580 PubMed abstracts annotated with ten currently known hallmarks of cancer (Baker et al., 2016). The multilabel classification task predicts multiple labels from the texts.
1.5. Inference Task
- MedNLI is a collection of sentence pairs selected from MIMIC-III (Romanov and Shivade, 2018). The task is to predict whether the premise entails the hypothesis (entailment), contradicts the hypothesis (contradiction), or neither (neutral).
1.6. Total Score
- A macro-average of F1-scores and Pearson scores.
2. Benchmarking Models & Results
2.1. BERT Pretraining

- In this paper, BERT is pre-trained on PubMed abstracts and clinical notes (MIMIC-III). The statistics of the text corpora on which BERT was pre-trained are shown in Table 2.
- BERT is initialized with pre-trained BERT provided by (Devlin et al., 2019), then continues to pre-train the model.
2.2. Fine-tuning with BERT
- BERT is applied to various downstream text-mining tasks with fine-tuning while requiring only minimal architecture modification.
- (Please read the paper for details.)
2.3. Fine-Tuning with ELMo
- The ELMo model pre-trained on PubMed abstracts is also adopted.
- (Please read the paper for details.)
2.4. Results
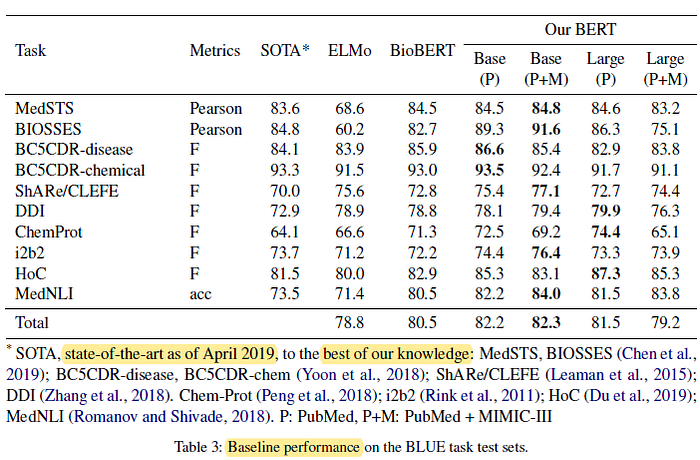
- Four BERT models are pretrained: BERT-Base (P), BERT-Large (P), BERT-Base (P+M), BERT-Large (P+M) on PubMed abstracts only, and the combination of PubMed abstracts and clinical notes, respectively.
Overall, the proposed BERT-Base (P+M) that were pretrained on both PubMed abstract and MIMIC-III achieved the best results across five tasks
- BERT-Large pre-trained on PubMed and MIMIC is worse than other models overall. This is partially because the MIMIC-III data are relatively smaller than the PubMed abstracts and, thus, cannot pretrain the large model sufficiently.
