Review — GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
GLUE: Nine Diverse Natural Language Understanding Tasks

GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding,
GLUE, by New York University, University of Washington, and DeepMind.
- The General Language Understanding Evaluation (GLUE, gluebenchmark.com): a benchmark of nine diverse natural language understanding (NLU) tasks, an auxiliary dataset for probing models for understanding of specific linguistic phenomena, and an online platform for evaluating and comparing models.
- The goal of GLUE is to spur development of generalizable NLU systems.
This is a paper in 2018 EMNLP Workshop with over 2300 citations. And it is later on published in 2019 ICLR with over 2100 citations. (Sik-Ho Tsang @ Medium)
Outline
- Nine Diverse Natural Language Understanding (NLU) Tasks
- Benchmark Results
- Diagnostic Dataset & Results
1. Nine Diverse Natural Language Understanding (NLU) Tasks

- There are single-sentence tasks, similarity and paraphrase tasks, and inference tasks.
1.1. CoLA (Corpus of Linguistic Acceptability)
- The Corpus of Linguistic Acceptability (Warstadt et al., 2018) consists of English acceptability judgments drawn from books and journal articles on linguistic theory.
- Each example is a sequence of words annotated with whether it is a grammatical English sentence.
1.2. SST-2 (Stanford Sentiment Treebank)
- The Stanford Sentiment Treebank (Socher et al., 2013) consists of sentences from movie reviews and human annotations of their sentiment.
- The task is to predict the sentiment of a given sentence. The two-way (positive/negative) class split is used, and use only sentence-level labels.
1.3. MRPC (Microsoft Research Paraphrase Corpus)
- The Microsoft Research Paraphrase Corpus (Dolan & Brockett, 2005) is a corpus of sentence pairs automatically extracted from online news sources, with human annotations for whether the sentences in the pair are semantically equivalent.
- Because the classes are imbalanced (68% positive), common practice is followed and both accuracy and F1 score are reported.
1.4. QQP (Quora Question Pairs)
- The Quora Question Pairs dataset is a collection of question pairs from the community question-answering website Quora.
- The task is to determine whether a pair of questions are semantically equivalent.
- As in MRPC, the class distribution in QQP is unbalanced (63% negative), both accuracy and F1 score are reported. Private labels are obtained from the authors in which the test set has a different label distribution than the training set.
1.5. STS-B (Semantic Textual Similarity Benchmark)
- The Semantic Textual Similarity Benchmark (Cer et al., 2017) is a collection of sentence pairs drawn from news headlines, video and image captions, and natural language inference data.
- Each pair is human-annotated with a similarity score from 1 to 5; the task is to predict these scores. Pearson and Spearman correlation coefficients are used for evaluation.
1.6. MNLI (Multi-Genre Natural Language Inference Corpus)
- The Multi-Genre Natural Language Inference Corpus (Williams et al., 2018) is a crowdsourced collection of sentence pairs with textual entailment annotations.
- The premise sentences are gathered from ten different sources, including transcribed speech, fiction, and government reports.
- Given a premise sentence and a hypothesis sentence, the task is to predict whether the premise entails the hypothesis (entailment), contradicts the hypothesis (contradiction), or neither (neutral).
- Authors also use and recommend the SNLI corpus (Bowman et al., 2015) as 550k examples of auxiliary training data.
1.7. QNLI (Stanford Question Answering Dataset)
- The Stanford Question Answering Dataset (Rajpurkar et al. 2016) is a question-answering dataset consisting of question-paragraph pairs, where one of the sentences in the paragraph (drawn from Wikipedia) contains the answer to the corresponding question (written by an annotator).
- The task is converted into sentence pair classification by forming a pair between each question and each sentence in the corresponding context, and filtering out pairs with low lexical overlap between the question and the context sentence. The task is to determine whether the context sentence contains the answer to the question.
- This converted dataset is called QNLI (Question-answering NLI)
1.8. RTE (Recognizing Textual Entailment)
- The Recognizing Textual Entailment (RTE) datasets come from a series of annual textual entailment challenges. The data is combined from RTE1 (Dagan et al., 2006), RTE2 (Bar Haim et al., 2006), RTE3 (Giampiccolo et al., 2007), and RTE5 (Bentivogli et al., 2009). Examples are constructed based on news and Wikipedia text.
- All datasets are converted to a two-class split, where for three-class datasets we collapse neutral and contradiction into not entailment, for consistency.
1.9. WNLI (Winograd Schema Challenge)
- The Winograd Schema Challenge (Levesque et al., 2011) is a reading comprehension task in which a system must read a sentence with a pronoun and select the referent of that pronoun from a list of choices. The examples are manually constructed to foil simple statistical methods: Each one is contingent on contextual information provided by a single word or phrase in the sentence.
- To convert the problem into sentence pair classification, sentence pairs are constructed by replacing the ambiguous pronoun with each possible referent. The task is to predict if the sentence with the pronoun substituted is entailed by the original sentence.
- This converted dataset is called WNLI (Winograd NLI).
2. Benchmark Results
2.1. Model
- The model uses a two-layer, 1500D (per direction) BiLSTM with max pooling and 300D GloVe word embeddings (840B Common Crawl version; Pennington et al., 2014).
- For single-sentence tasks, the sentence is encoded and the resulting vector is passed to a classifier.
- For sentence-pair tasks, sentences are encoded independently to produce vectors u and v. and [u, v, |u-v|, u*v] are passed to a classifier. The classifier is an MLP with a 512D hidden layer.
2.2. Pretraining
- ELMo and CoVe are considered.
- ELMo uses a pair of two-layer neural language models trained on the Billion Word Benchmark (Chelba et al., 2013). Each word is represented by a contextual embedding, produced by taking a linear combination of the corresponding hidden states of each layer of the two models.
- (Hope I can review ELMo in the future.)
- CoVe (McCann et al., 2017) uses a two-layer BiLSTM encoder originally trained for English-to-German translation. The CoVe vector of a word is the corresponding hidden state of the top-layer LSTM. As in the original work, the CoVe vectors are concatenated to the GloVe word embeddings.
2.3. Results
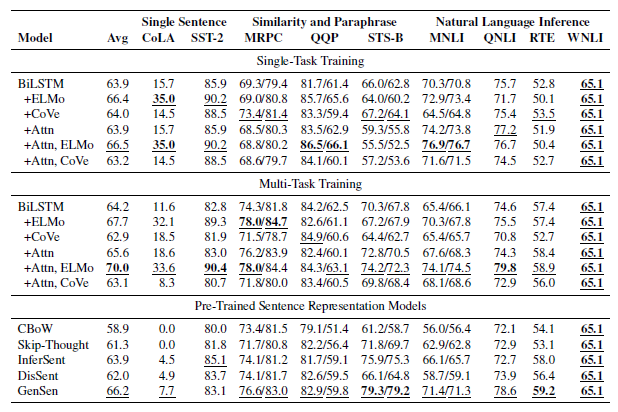
- For MNLI, accuracy is reported on the matched and mismatched test sets.
- For MRPC and Quora, accuracy and F1 are reported .
- For STS-B, Pearson and Spearman correlation is reported.
- For CoLA, Matthews correlation is reported .
- For all other tasks, accuracy is reported. All values are scaled by 100.
Multi-task training yields better overall scores over single-task training amongst models using attention or ELMo.
- A consistent improvement is observed in using ELMo embeddings in place of GloVe or CoVe embeddings, particularly for single-sentence tasks.
- Using CoVe has mixed effects over using only GloVe.
Among the pre-trained sentence representation models, fairly consistent gains are observed moving from CBoW (in Word2Vec) to Skip-Thought to Infersent and GenSen.
- Relative to the models trained directly on the GLUE tasks, InferSent is competitive and GenSen outperforms all but the two best.
3. Diagnostic Dataset & Results
3.1. Diagnostic Dataset

- It is a small, manually-curated test set for the analysis of system performance.
- Each diagnostic example is an NLI sentence pair with tags for the phenomena demonstrated.
3.2. Results

Overall performance is low for all models. The highest total score of 28 still denotes poor absolute performance.
- For example, double negation is especially difficult for the GLUE-trained models that only use GloVe embeddings.
References
[2018 EMNLP Workshop] [GLUE]
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
[2019 ICLR] [GLUE]
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
Natural Language Processing (NLP)
Language/Sequence Model: 2007 [Bengio TNN’07] 2013 [Word2Vec] [NCE] [Negative Sampling] 2014 [GloVe] [GRU] [Doc2Vec] 2015 [Skip-Thought] 2016 [GCNN/GLU] [context2vec] [Jozefowicz arXiv’16] [LSTM-Char-CNN] 2017 [TagLM] [CoVe] [MoE] 2018 [GLUE] 2019 [GLUE]
Machine Translation: 2014 [Seq2Seq] [RNN Encoder-Decoder] 2015 [Attention Decoder/RNNSearch] 2016 [GNMT] [ByteNet] [Deep-ED & Deep-Att] 2017 [ConvS2S] [Transformer] [MoE]
Image Captioning: 2015 [m-RNN] [R-CNN+BRNN] [Show and Tell/NIC] [Show, Attend and Tell]
