Review: Data Efficient Image Transformer (DeiT)
DeiT: Train Vision Transformer (ViT) Without External Data

Training Data-Efficient Image Transformers & Distillation Through Attention, DeiT, Data-Efficient Image Transformers, by Facebook AI, Sorbonne University
2021 ICML, Over 600 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Transformer, Vision Transformer, Teacher Student, Pseudo Label, Distillation
- Prior Vision Transformer, ViT, needs to be pre-trained with hundreds of millions of images using external data. ViT does not generalize well when trained on insufficient amounts of data.
- Data-Efficient Image Transformer, DeiT, is proposed. While the architecture is mostly the same as ViT, it is trained on ImageNet only using a single computer in less than 3 days, with no external data.
- A teacher-student strategy is introduced with distillation token.
Outline
- Distillation Through Attention
- Experimental Results
1. Distillation Through Attention
- DeiT has the same architecture as ViT except the input token part that having an additional distillation token. But since ViT cannot perform well when trained on insufficient amounts of data. Distillation is a way to train.
One solution is that, assume we have access to a strong image classifier as a teacher model. Can the Transformer learnt by exploiting this teacher?
- Two things are considered: hard vs soft distillation, and classical distillation vs distillation token.
1.1. Soft Distillation
- Soft distilllation minimizes the Kullback-Leibler (KL) divergence between the softmax of the teacher and the softmax of the student model.
- Let Zt be the logits of the teacher , Zs the logits of the student.
- The distillation objective is:

- τ is temperature (Distillation) and λ is coefficient balancing KL divergence and cross entropy loss.
1.2. Hard Label Distillation
- Hard decision of the teacher is used as true label:

- The objective associated with this hard-label distillation is:

- For a given image, the hard label associated with the teacher may change depending on the specific data augmentation.
This choice is better than the traditional one, while being parameter-free and conceptually simpler: The teacher prediction yt plays the same role as the true label y.
- Hard label can still be converted to soft label using label smoothing (Inception-v3). But in this paper, authors do not smooth pseudo-labels provided by the teacher (e.g., in hard distillation).
1.3. Distillation Token

- A new distillation token is included. It interacts with the class and patch tokens through the self-attention layers.
- This distillation token is employed in a similar fashion as the class token, except that on output of the network its objective is to reproduce the (hard) label predicted by the teacher, instead of true label.
- Both the class and distillation tokens input to the transformers are learned by back-propagation.
- The distillation embedding allows the model to learn from the output of the teacher, as in a regular distillation.
1.4. Models & Inference

- DeiT does not use a MLP head for the pre-training but only a linear classifier.
- DeiT-B is ViT-B architecture using proposed training scheme and distillation token. The parameters of ViT-B (and therefore of DeiT-B) are fixed as D=768, h=12 and d=D/h=64.
- Two smaller models, namely DeiT-S and DeiT-Ti, are also introduced, for which the number of heads is changed while keeping d fixed.
- When fine-tuning, larger resolution is used (FixRes). DeiT-B↑384 where 384 is the resulting operating resolution at the end.
- At test time, both the class or the distillation embeddings produced by the transformer are associated with linear classifiers and able to infer the image label.
- The referent method is the late fusion of these two separate heads, for which the softmax output is added by the two classifiers to make the prediction.
2. Experimental Results
2.1. ConvNet Teacher

- Using a convnet teacher gives better performance than using a transformer.
- The convnet is a better teacher is probably due to the inductive bias inherited by the transformers through distillation.
- In all of the subsequent distillation experiments the default teacher is a RegNetY-16GF with 84M parameters, that the same data and same data-augmentation are used as DeiT. This teacher reaches 82.9% top-1 accuracy on ImageNet.
2.2. Distillation Methods

- Hard distillation significantly outperforms soft distillation. Hard distillation reaches 83.0% at resolution 224×224, compared to the soft distillation accuracy of 81.8%.
- The two tokens provide complementary information useful for classification. The classifier on the two tokens is significantly better than the independent class and distillation classifiers, which by themselves already outperform the distillation baseline.
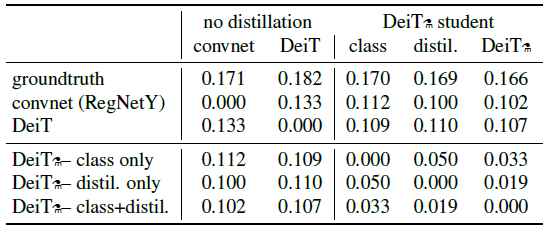
- The fraction of sample classified differently for all classifier pairs, i.e., the rate of different decisions, is reported.
The distilled model is more correlated to the convnet than with a transformer learned from scratch.
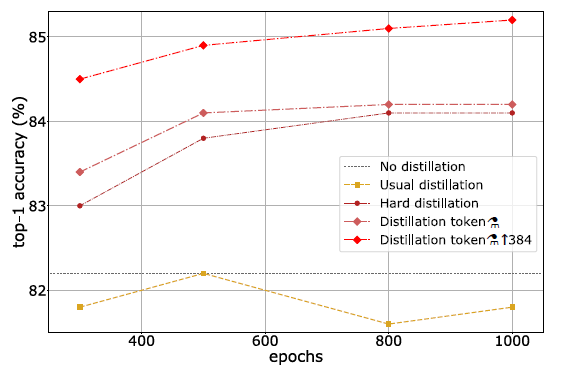
- With 300 epochs, the distilled network DeiT-B⚗ is already better than DeiT-B.
2.3. Efficiency vs Accuracy: A Comparison to Convnets
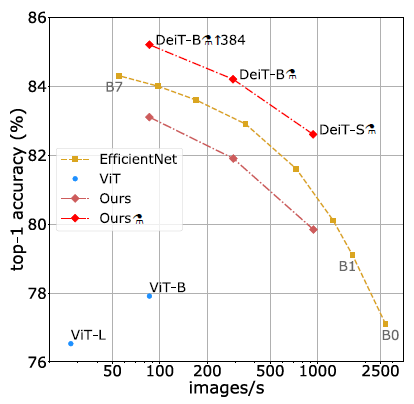
- DeiT is slightly below EfficientNet, which shows that DeiT have almost closed the gap between Vision Transformers and convnets when training with ImageNet only.
- These results are a major improvement (+6.3% top-1 in a comparable setting) over previous ViT models trained on ImageNet1k only.
Furthermore, when DeiT benefits from the distillation from a relatively weaker RegNetY to produce DeiT⚗, it outperforms EfficientNet.
- It also outperforms by 1% (top-1 acc.) the ViT-B model pre-trained on JFT300M at resolution 384 (85.2% vs 84.15%), while being significantly faster to train.
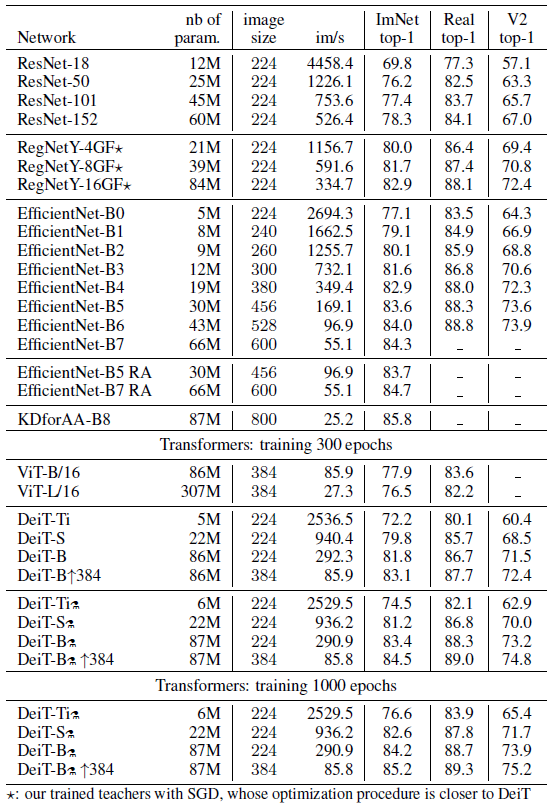
- The best model on ImageNet-1k is 85.2% top-1 accuracy outperforms the best ViT-B model pre-trained on JFT-300M and fine-tuned on ImageNet-1k at resolution 384 (84.15%).
- ImageNet V2 and ImageNet Real are also evaluated.
- Note, the current state of the art of 88.55% achieved with extra training data is the ViT-H model (632M parameters) trained on JFT-300M and fine-tuned at resolution 512.
- DeiT-B⚗ and DeiT-B⚗ “384 outperform, by some margin, the state of the art on the trade-off between accuracy and inference time on GPU.
2.4. Transfer Learning to Downstream Tasks
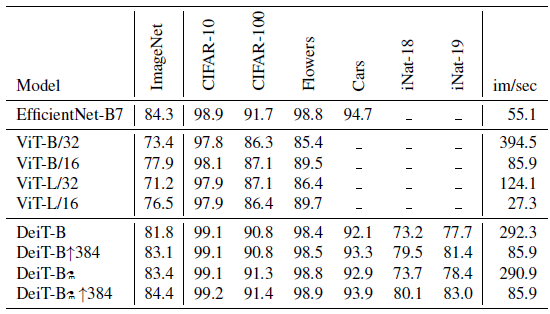
DeiT is on par with competitive convnet models.
2.5. Training Details & Ablation

2.6. Training Time
- A typical training of 300 epochs takes 37 hours with 2 nodes or 53 hours on a single 8-GPU node for the DeiT-B.
- As a comparison point, a similar training with a RegNetY-16GF (Radosavovic et al., 2020) (84M parameters) is 20% slower.
- DeiT-S and DeiT-Ti are trained in less than 3 days on 4 GPU.
- Then, optionally the model is fine-tuned at a larger resolution. This takes 20 hours on 8 GPUs to fine-tune a DeiT-B model at resolution 384×384, which corresponds to 25 epochs.
Reference
[2021 ICML] [DeiT]
Training Data-Efficient Image Transformers & Distillation Through Attention
Image Classification
1989–2018 … 2019: [ResNet-38] [AmoebaNet] [ESPNetv2] [MnasNet] [Single-Path NAS] [DARTS] [ProxylessNAS] [MobileNetV3] [FBNet] [ShakeDrop] [CutMix] [MixConv] [EfficientNet] [ABN] [SKNet] [CB Loss] [AutoAugment, AA] [BagNet] [Stylized-ImageNet] [FixRes] [Ramachandran’s NeurIPS’19] [SE-WRN] [SGELU] [ImageNet-V2]
2020: [Random Erasing (RE)] [SAOL] [AdderNet] [FixEfficientNet] [BiT] [RandAugment]
2021: [Learned Resizer] [Vision Transformer, ViT] [ResNet Strikes Back] [DeiT]
