Review — GRF-DSOD & GRF-SSD: Improving Object Detection from Scratch via Gated Feature Reuse (Object Detection)
Outperforms DSOD, DSSD, SSD, R-FCN, Faster R-CNN, DCN / DCNv1, FPN With Fewer Parameters

In this paper, Improving Object Detection from Scratch via Gated Feature Reuse, (GRF-DSOD & GRF-SSD), by Carnegie Mellon University, University of Illinois at Urbana-Champaign, IBM Research AI, MIT-IBM Watson AI Lab, Google AI & UMass Amherst, and Stevens Institute of Technology, is reviewed. In this paper:
- A Gated Feature Reuse (GFR) module is proposed, to enable Squeeze-and-Excitation to adaptively enhance or attenuate supervision.
- A feature-pyramids structure to squeeze rich spatial and semantic features into a single prediction layer, which strengthens feature representation and reduces the number of parameters to learn.
- It is noted that this network can be trained from scratched, no need ImageNet pre-training.
This is a paper in 2019 BMVC. (Sik-Ho Tsang @ Medium)
1. Iterative Feature Re-Utilization

- As in DSOD (The first figure), the feature maps at different scales are generated the large-scale feature maps are downsampled and concatenated with the current feature maps.
- Here, except the downsampled feature maps, the small-scale feature maps are upsampled and concatenated with the current feature maps as well.
- The downsampling pathway consists mainly of a max pooling layer (kernel size=2×2, stride=2), followed by a conv-layer (kernel size=1×1, stride = 1) to reduce channel dimensions.
- The up-sampling pathway conducts a deconvolutional operation via bilinear upsampling followed by a conv-layer (kernel size = 1×1, stride = 1).
- With coarser-resolution and fine-resolution features, a bottleneck block with a 1×1 conv-layer plus a 3×3 conv-layer is introduced to learn new features.
- The number of parameters is one-third compared with DSOD.

With the upsampling and downsampling, feature maps at different scales can be concatenated together to detect different sizes of objects, as shown above.
2. Gate-Controlled Adaptive Recalibration

2.1. Channel-Level Attention
- The Squeeze-and-Excitation block in SENet is used.
- The squeeze stage can be formulated as a global pooling operation on U:

- The excitation stage is two fully-connected layers plus a sigmoid activation:

- where σ is the sigmoid function.
- Then, ~U is calculated by:
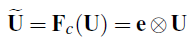
where ⨂ denotes channel-wise multiplication.
2.2. Global-Level Attention
- The global attention takes s (the output of squeeze stage) as input, and generates only one element.
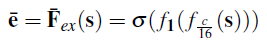
- where ¯e is the global attention.
- Finally, ~V is calculated by:
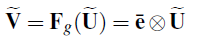
2.3. Identity Mapping
- An element-wise addition operation is performed to obtain the final output:
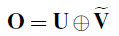
3. Feature Reuse for DSOD and SSD
- The proposed method is a generic solution for building iterative feature pyramids and gates inside deep convolutional neural networks based detectors, thus it’s very easy to apply to existing frameworks.
3.1. GRF-DSOD
- There are two steps to adapt Gated Feature Reuse for DSOD.
- First, the iterative feature reuse is to replace the dense connection in DSOD prediction layers.
- Following that, gates are added in each prediction layer.
3.2. GRF-SSD
4. Experimental Results
- It is noted that this network can be trained from scratched, no need ImageNet pre-training.
- For VOC 2007, the network is trained using the union of VOC 2007 trainval and VOC 2012 trainval (“07+12”) and test on VOC 2007 test set.
- For VOC 2012, the network is trained usingVOC 2012 trainval and VOC 2007 trainval + test for training, and test on VOC 2012 test set.
- For COCO, 80k images in training set, 40k in validation set and 20k in testing set (test-dev).
4.1. Ablation Experiments on PASCAL VOC 2007

- After adopting channel attention, global attention and identity mapping, we obtain gains of 0.4%, 0.2% and 0.2%, respectively.
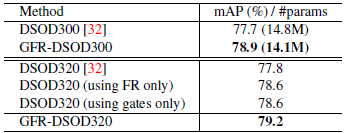
- The results of the feature pyramids without the gates (78.6%) is on par with GFR-DSOD320 (row 6) and achieves 0.8% improvement comparing with baseline (77.8%).
- It indicates that our feature reuse structure contribute a lot on boosting the final detection performance.
- The results of adding gates without the iterative feature pyramids (78.6%) also outperforms the baseline result by 0.8% mAP.
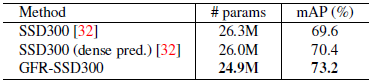
- Also, GFR structure helps the original SSD to improve the performance by a large margin.
4.2. Results on PASCAL VOC 2007 & 2012
- In the second table, GFR-DSOD achieves 79.2%, which is better than baseline method DSOD (77.8%).

- The proposed method achieves better results on both small objects and dense scenes.

- Thus, GFR-DSOD has relative 38% faster convergence speed than DSOD.
- For the inference time, With 300×300 input, the full GFR-DSOD can run an image at 17.5 fps on a single Titan X GPU with batch size 1. The speed is similar to DSOD300 with the dense prediction structure.
- When enlarging the input size to 320×320, the speed decrease to 16.7 fps and 16.3 fps (with more default boxes).
- As comparisons, SSD321 runs at 11.2 fps and DSSD321 runs at 9.5 fps with ResNet-101 backbone network. The method is much faster than these two competitors.
- On PASCAL VOC 2012 Comp3 Challenge, GFR-DSOD result (72.5%) outperforms the previous state-of-the-art DSOD (70.8%) by 1.7% mAP.
- After adding VOC 2007 as training data, 77.5% mAP is obtained.
4.3. Results on MS COCO

- GFR-DSOD can achieve higher performance than the baseline method DSOD (30.0% vs. 29.4%) with fewer parameters (21.2M vs. 21.9M).
- The result is comparable with FPN320/540 [22] (30.0% vs. 29.7%), but the parameters of the model is only 1/6 of FPN.
- So, finally, GFR-DSOD outperforms DSOD, DSSD, SSD, R-FCN, Faster R-CNN, DCN / DCNv1, and FPN for {0.5:0.95} mAP.
Reference
[2019 BMVC] [GRF-DSOD & GRF-SSD]
Improving Object Detection from Scratch via Gated Feature Reuse
Object Detection
2014: [OverFeat] [R-CNN]
2015: [Fast R-CNN] [Faster R-CNN] [MR-CNN & S-CNN] [DeepID-Net]
2016: [CRAFT] [R-FCN] [ION] [MultiPathNet] [Hikvision] [GBD-Net / GBD-v1 & GBD-v2] [SSD] [YOLOv1]
2017: [NoC] [G-RMI] [TDM] [DSSD] [YOLOv2 / YOLO9000] [FPN] [RetinaNet] [DCN / DCNv1] [Light-Head R-CNN] [DSOD]
2018: [YOLOv3] [Cascade R-CNN] [MegDet] [StairNet]
2019: [DCNv2] [Rethinking ImageNet Pre-training] [GRF-DSOD & GRF-SSD]

