Review — HRNet / HRNetV1: Deep High-Resolution Representation Learning for Human Pose Estimation
HRNet / HRNetV1, Maintains High Resolution & Fusion Across Different Resolutions.
Deep High-Resolution Representation Learning for Human Pose Estimation,
HRNet, HRNetV1, by University of Science and Technology of China, and Microsoft Research Asia,
2019 CVPR, Over 2900 Citations (Sik-Ho Tsang @ Medium)Human Pose Estimation
2014–2015 [DeepPose] [Tompson NIPS’14] [Tompson CVPR’15] 2016 [CPM] [FCGN] [IEF] [DeepCut & DeeperCut] [Newell ECCV’16 & Newell POCV’16] 2017 [G-RMI] [CMUPose & OpenPose] [Mask R-CNN] 2018 [PersonLab]
==== My Other Paper Readings Are Also Over Here ====
- Most existing methods uses a high-to-low resolution network.
- Instead, the proposed network, HRNet or HRNetV1, maintains high-resolution representations through the whole process.
- Later, HRNetV2 is also proposed.
Outline
- HRNet or HRNetV1
- Results
1. HRNet or HRNetV1
1.1. Development of HRNet

- Let Nsr be the subnetwork in the s-th stage and r be the resolution index. The high-to-low network with S (e.g., 4) stages can be denoted as:

- An example network structure, containing 4 parallel subnetworks:

- But there is no information sharing among subnetworks.

Exchange units are introduced across parallel subnetworks such that each subnetwork repeatedly receives the information from other parallel subnetworks.
Finally, the HRNet is proposed as in the first figure.
1.2. Model Variants
- HRNet, contains four stages with four parallel subnetworks.
- The first stage contains 4 residual units where each unit, the same to the ResNet-50. The 2nd, 3rd, 4th stages contain 1, 4, 3 exchange blocks, respectively. There are totally 8 exchange units, i.e., 8 multi-scale fusions are conducted.
- HRNet-W32 and HRNet-W48, where 32 and 48 represent the widths (C) of the high-resolution subnetworks in last three stages, respectively.
- The widths of other three parallel subnetworks are 64, 128, 256 for HRNet-W32, and 96, 192, 384 for HRNet-W48.
2. Results
2.1. COCO

HRNet is significantly better than bottom-up approaches.
2.2. MPII

HRNet is the same as the best one [60] among the previously published results on the leaderboard of Nov. 16th, 2018. The reason might be that the performance in this dataset tends to be saturate.
2.3. PoseTrack2017
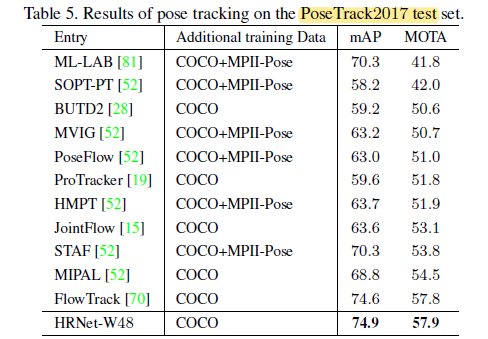
- This dataset is a dataset for human pose estimation and articulated tracking in video.
HRNet gets 0.3 and 0.1 points gain in terms of mAP and MOTA, respectively.
2.4. Further Studies

The multi-scale fusion is helpful and more fusions lead to better performance.
The simple high-resolution network of similar parameter and GFLOPs without low-resolution parallel subnetworks shows much lower performance.
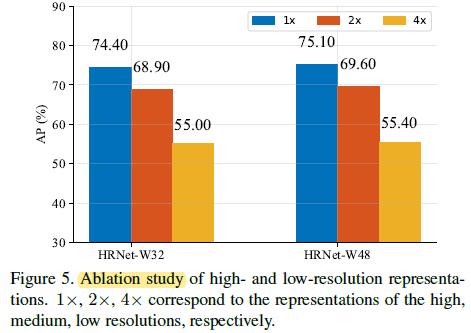
The resolution does impact the keypoint prediction quality.
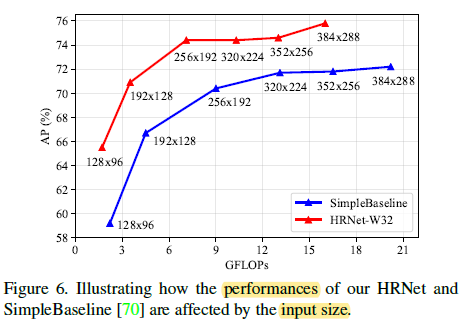
HRNet with the input size 256 × 192 outperforms the SimpleBaseline with the large input size of 384 × 288.

HRNet can detect keypoints, even they are containing viewpoint and appearance change, occlusion, multiple persons, and common imaging artifacts.
